If you want to know more about Datomisca/Datomic schema go to my recent article. What’s interesting with Datomisca schema is that they are statically typed allowing some compiler validations and type inference.
HList are able to contain different types of data and able to keep tracks of these types.
This project is an experience trying to :
convert HList to/from Datomic Entities
check HList types against schema at compile-time
This uses :
Datomisca type-safe schema
Shapeless HList
Shapeless polymorphic functions
Please note that we don’t provide any Iso[From, To] since there is no isomorphism here.
Actually, there are 2 monomorphisms (injective):
HList => AddEntity to provision an entity
DEntity => HList when retrieving entity
We would need to implement Mono[From, To] certainly for our case…
Code sample
Create schema based on HList
123456789101112131415161718192021
// Koala SchemaobjectKoala{objectns{valkoala=Namespace("koala")}// schema attributesvalname=Attribute(ns.koala/"name",SchemaType.string,Cardinality.one).withDoc("Koala's name")valage=Attribute(ns.koala/"age",SchemaType.long,Cardinality.one).withDoc("Koala's age")valtrees=Attribute(ns.koala/"trees",SchemaType.string,Cardinality.many).withDoc("Koala's trees")// the schema in HList formvalschema=name::age::trees::HNil// the datomic facts corresponding to schema // (need specifying upper type for shapeless conversion to list)valtxData=schema.toList[Operation]}// Provision schemaDatomic.transact(Koala.txData)map{tx=>...}
Validate HList against Schema
1234567891011121314151617181920212223
// creates a Temporary ID & keeps it for resolving entity after insertionvalid=DId(Partition.USER)// creates an HList entity valhListEntity=id::"kaylee"::3L::Set("manna_gum","tallowwood")::HNil// validates and converts at compile-time this HList against schemahListEntity.toAddEntity(Koala.schema)// If you remove a field from HList and try again, the compiler failsvalbadHListEntity=id::"kaylee"::Set("manna_gum","tallowwood")::HNilscala>badHListEntity.toAddEntity(Koala.schema)<console>:23:error:couldnotfindimplicitvalueforparameterpull:shapotomic.SchemaCheckerFromHList.Pullback2[shapeless.::[datomisca.TempId,shapeless.::[String,shapeless.::[scala.collection.immutable.Set[String],shapeless.HNil]]],
shapeless.::[datomisca.RawAttribute[datomisca.DString,datomisca.CardinalityOne.type],
shapeless.::[datomisca.RawAttribute[datomisca.DLong,datomisca.CardinalityOne.type],
shapeless.::[datomisca.RawAttribute[datomisca.DString,datomisca.CardinalityMany.type],shapeless.HNil]]],datomisca.AddEntity]
The compiler error is a bit weird at first but if you take a few seconds to read it, you’ll see that there is nothing hard about it, it just says:
Convert DEntity to static-typed HList based on schema
1234567
vale=Datomic.resolveEntity(tx,id)// rebuilds HList entity from DEntity statically typed by schemavalpostHListEntity=e.toHList(Koala.schema)// Explicitly typing the value to show that the compiler builds the right typed HList from schemavalvalidateHListEntityType:Long::String::Long::Set[String]::HNil=postHListEntity
Conclusion
Using HList with compile-time schema validation is quite interesting because it provides a very basic and versatile data structure to manipulate Datomic entities in a type-safe style.
Moreover, as Datomic pushes atomic data manipulation (simple facts instead of full entities), it’s really cool to use HList instead of rigid static structure such as case-class.
One more step in our progressive unveiling of Datomisca, our opensource Scala API (sponsored by Pellucid & Zenexity) trying to enhance Datomic experience for Scala developers…
As explained in previous articles, Datomic stores lots of atomic facts called datoms which are constituted of entity-id, attribute, value and transaction-id.
An attribute is just a namespaced keyword :<namespace>.<nested-namespace>/<name> such as:person.address/street`:
person.address is just a hierarchical namespace person -> address
street is the name of the attribute
It’s cool to provision all thoses atomic pieces of information but what if we provision non existing attribute with bad format, type, …? Is there a way to control the format of data in Datomic?
In a less strict way than SQL, Datomic provides schema facility allowing to constrain the accepted attributes and their type values.
Schema attribute definition
Datomic schema just defines the accepted attributes and some constraints on those attributes. Each schema attribute can be defined by following fields:
The schema validation is applied at fact insertion and allows to prevent from inserting unknown attributes or bad value types. But how are schema attributes defined?
Actually, schema attributes are themselves entities.
Remember, in previous article, I had introduced entities as being just loose aggregation of datoms just identified by the same entity ID (the first attribute of a datom).
So a schema attribute is just an entity stored in a special partition :db.part/db and defined by a few specific fields corresponding to the ones in previous paragraph. Here are the fields used to define a Datomic schema attribute technically speaking:
mandatory fields
:db/ident : specifies unique name of the attribute
:db/valueType : specifies one the previous types - Please note that even those types are not hard-coded in Datomic and in the future, adding new types could be a new feature.
:db/cardinality : specifies the cardinality one or many of the attribute - a many attribute is just a set of values and type Set is important because Datomic only manages sets of unique values as it won’t return multiple times the same value when querying.
optional fields
:db/unique
:db/doc (useful to document your schema)
:db/index
:db/fulltext
:db/isComponent
:db/noHistory
Here is an example of schema attribute declaration written in Clojure:
As you can see, creating schema attributes just means creating new entities in the right partition. So, to add new attributes to Datomic, you just have to add new facts.
Schema sample
Let’s create a schema defining a Koala living in an eucalyptus.
Yes I’m a super-Koala fan! Don’t ask me why, this is a long story not linked at all to Australia :D… But saving Koalas is important to me so I put this little banner for them…
Let’s define a koala by following attributes:
a name String
an age Long
a sex which can be male or `female
a few eucalyptus trees in which to feed defined by:
a species being a reference to one of the possible species of eucalyptus trees
a row Long (let’s imagine those trees are planted in rows/columns)
Now, you must know it but Datomisca intensively uses Scala 2.10 macros to provide compile-time parsing and validation of Datomic queries or operations written in Clojure.
Previous Schema attributes definition is just a set of classic operations so you can ask Datomisca to parse them at compile-time as following:
Then you can provision the schema into Datomic using:
12345
Datomic.transact(ops)map{tx=>...// do something//}
The preferred way
Ok the previous is cool as you can validate and provision a clojure schema using Datomisca.
But Datomisca provides a programmatic way of writing schema in Scala. This brings :
// Sex SchemaobjectSexSchema{// First create your namespaceobjectns{valsex=Namespace("sex")}// enumerated valuesvalFEMALE=AddIdent(ns.sex/"female")// :sex/femalevalMALE=AddIdent(ns.sex/"male")// :sex/male// facts representing the schema to be provisionedvaltxData=Seq(FEMALE,MALE)}// Eucalyptus SchemaobjectEucalyptusSchema{objectns{valeucalyptus=newNamespace("eucalyptus"){// new is just here to allow structural constructionvalspecies=Namespace("species")}}// different speciesvalMANNA_GUM=AddIdent(ns.eucalyptus.species/"manna_gum")valTASMANIAN_BLUE_GUM=AddIdent(ns.eucalyptus.species/"tasmanian_blue_gum")valSWAMP_GUM=AddIdent(ns.eucalyptus.species/"swamp_gum")valGRY_GUM=AddIdent(ns.eucalyptus.species/"grey_gum")valRIVER_RED_GUM=AddIdent(ns.eucalyptus.species/"river_red_gum")valTALLOWWOOD=AddIdent(ns.eucalyptus.species/"tallowwood")// schema attributesvalspecies=Attribute(ns.eucalyptus/"species",SchemaType.ref,Cardinality.one).withDoc("Eucalyptus's species")valrow=Attribute(ns.eucalyptus/"row",SchemaType.long,Cardinality.one).withDoc("Eucalyptus's row")valcol=Attribute(ns.eucalyptus/"col",SchemaType.long,Cardinality.one).withDoc("Eucalyptus's column")// facts representing the schema to be provisionedvaltxData=Seq(species,row,col,MANNA_GUM,TASMANIAN_BLUE_GUM,SWAMP_GUM,GRY_GUM,RIVER_RED_GUM,TALLOWWOOD)}// Koala SchemaobjectKoalaSchema{objectns{valkoala=Namespace("koala")}// schema attributesvalname=Attribute(ns.koala/"name",SchemaType.string,Cardinality.one).withDoc("Koala's name").withUnique(Unique.value)valage=Attribute(ns.koala/"age",SchemaType.long,Cardinality.one).withDoc("Koala's age")valsex=Attribute(ns.koala/"sex",SchemaType.ref,Cardinality.one).withDoc("Koala's sex")valeucalyptus=Attribute(ns.koala/"eucalyptus",SchemaType.ref,Cardinality.many).withDoc("Koala's trees")// facts representing the schema to be provisionedvaltxData=Seq(name,age,sex,eucalyptus)}// Provision Schema by just accumulating all txDataDatomic.transact(SexSchema.txData++EucalyptusSchema.txData++KoalaSchema.txData)map{tx=>...}
Nothing complicated, isn’t it?
Exactly the same as writing Clojure schema but in Scala…
Datomisca type-safe schema
Datomisca takes advantage of Scala type-safety to enhance Datomic schema attribute and make them static-typed. Have a look at Datomisca Attribute definition:
SchemaType.string implies this is a Attribute[DString, _]
Cardinality.one implies this is a `Attribute[_, Cardinality.one]
So name is a Attribute[DString, Cardinality.one]
In the same way:
age is Attribute[DLong, Cardinality.one]
sex is Attribute[DRef, Cardinality.one]
eucalyptus is Attribute[DRef, Cardinality.many]
As you can imagine, using this type-safe schema attributes, Datomisca can ensure consistency between the Datomic schema and the types manipulated in Scala.
Taking advantage of type-safe schema
Checking types when creating facts
Based on the typed attribute, the compiler can help us a lot to validate that we give the right type for the right attribute.
Schema facilities are extensions of basic Datomisca so you must import following to use them:
1
importDatomicMapping._
Here is a code sample:
12345678910111213141516171819202122232425
//////////////////////////////////////////////////////////////////////// correct tree with right typesscala>valtree58=SchemaEntity.add(DId(Partition.USER))(Props()+(EucalyptusSchema.species->EucalyptusSchema.SWAMP_GUM.ref)+(EucalyptusSchema.row->5L)+(EucalyptusSchema.col->8L))tree58:datomisca.AddEntity={:eucalyptus/species:species/swamp_gum:eucalyptus/row5:eucalyptus/col8:db/id#db/id[:db.part/user-1000000]}//////////////////////////////////////////////////////////////////////// incorrect tree with a string instead of a long for rowscala>valtree58=SchemaEntity.add(DId(Partition.USER))(Props()+(EucalyptusSchema.species->EucalyptusSchema.SWAMP_GUM.ref)+(EucalyptusSchema.row->"toto")+(EucalyptusSchema.col->8L))<console>:18:error:couldnotfindimplicitvalueforparameterattrC:datomisca.Attribute2PartialAddEntityWriter[datomisca.DLong,datomisca.CardinalityOne.type,String](EucalyptusSchema.species->EucalyptusSchema.SWAMP_GUM.ref)+
In second case, compiling fails because DLong => String doesn’t exist.
In first case, it works because DLong => Long is valid.
Checking types when getting fields from Datomic entities
First of all, let’s create our first little Koala named Rose which loves feeding from 2 eucalyptus trees.
What’s important here is that you get a (String, Long, Long, Set[Long]) which means the compiler was able to infer the right types from the Schema Attribute…
Greattt!!!
Ok that’s all for today!
Next article about an extension Datomisca provides for convenience : mapping Datomic entities to Scala structures such as case-classes or tuples. We don’t believe this is really the philosophy of Datomic in which atomic operations are much more interesting. But sometimes it’s convenient when you want to have data abstraction layer…
Do you like Shapeless, this great API developed by Miles Sabin studying generic/polytypic programming in Scala?
Do you like Play-json, the Play Json 2.1 Json API developed for Play 2.1 framework and now usable as stand-alone module providing functional & typesafe Json validation and Scala conversion?
Here is Shapelaysson an API interleaving Play-Json with Shapeless to be able to manipulate Json from/to Shapeless HList
HList are heterogenous polymorphic lists able to contain different types of data and able to keep tracks of these types
Shapelaysson is a Github project with test/samples
Shapelaysson takes part in my reflexions around manipulating pure data structures from/to JSON.
importplay.api.libs.json._importshapeless._importHList._importTuples._importshapelaysson._// validates + converts a JsArray into HListscala>Json.arr("foo",123L).validate[String::Long::HNil]res1:play.api.libs.json.JsResult[shapeless.::[String,shapeless.::[Long,shapeless.HNil]]]=JsSuccess(foo::123::HNil,)// validates + converts a JsObject into HListscala>Json.obj("foo"->"toto","bar"->123L).validate[String::Long::HNil]res3:play.api.libs.json.JsResult[shapeless.::[String,shapeless.::[Long,shapeless.HNil]]]=JsSuccess(toto::123::HNil,)// validates + converts imbricated JsObject into HListscala>Json.obj(|"foo"->"toto",|"foofoo"->Json.obj("barbar1"->123.45,"barbar2"->"tutu"),|"bar"->123L,|"barbar"->Json.arr(123,true,"blabla")|).validate[String::(Float::String::HNil)::Long::(Int::Boolean::String::HNil)::HNil]res4:play.api.libs.json.JsResult[shapeless.::[String,shapeless.::[shapeless.::[Float,shapeless.::[String,shapeless.HNil]],shapeless.::[Long,shapeless.::[shapeless.::[Int,shapeless.::[Boolean,shapeless.::[String,shapeless.HNil]]],shapeless.HNil]]]]]=JsSuccess(toto::123.45::tutu::HNil::123::123::true::blabla::HNil::HNil,)// validates with ERROR JsArray into HListscala>Json.arr("foo",123L).validate[Long::Long::HNil]mustbeEqualTo(JsError("validate.error.expected.jsnumber"))<console>:23:error:valuemustisnotamemberofplay.api.libs.json.JsResult[shapeless.::[Long,shapeless.::[Long,shapeless.HNil]]]Json.arr("foo",123L).validate[Long::Long::HNil]mustbeEqualTo(JsError("validate.error.expected.jsnumber"))// converts HList to JsValuescala>Json.toJson(123.45F::"tutu"::HNil)res6:play.api.libs.json.JsValue=[123.44999694824219,"tutu"]
importplay.api.libs.functional.syntax._// creates a Reads[ String :: Long :: (String :: Boolean :: HNil) :: HNil]scala>valHListReads2=(|(__\"foo").read[String]and|(__\"bar").read[Long]and|(__\"toto").read(|(|(__\"alpha").read[String]and|(__\"beta").read[Boolean]|).tupled.hlisted|)|).tupled.hlistedHListReads2:play.api.libs.json.Reads[shapeless.::[String,shapeless.::[Long,shapeless.::[shapeless.::[String,shapeless.::[Boolean,shapeless.HNil]],shapeless.HNil]]]]=play.api.libs.json.Reads$$anon$8@7e4a09ee// validates/converts JsObject to HListscala>Json.obj(|"foo"->"toto",|"bar"->123L,|"toto"->Json.obj(|"alpha"->"chboing",|"beta"->true|)|).validate(HListReads2)res7:play.api.libs.json.JsResult[shapeless.::[String,shapeless.::[Long,shapeless.::[shapeless.::[String,shapeless.::[Boolean,shapeless.HNil]],shapeless.HNil]]]]=JsSuccess(toto::123::chboing::true::HNil::HNil,)// Create a Writes[String :: Long :: HNil]scala>implicitvalHListWrites:Writes[String::Long::HNil]=(|(__\"foo").write[String]and|(__\"bar").write[Long]|).tupled.hlistedHListWrites:play.api.libs.json.Writes[shapeless.::[String,shapeless.::[Long,shapeless.HNil]]]=play.api.libs.json.Writes$$anon$5@7c9d07e2// writes a HList to JsValuescala>Json.toJson("toto"::123L::HNil)res8:play.api.libs.json.JsValue={"foo":"toto","bar":123}
A short article to talk about an interesting issue concerning Scala 2.10.0 Future that might interest you.
Summary
When a Fatal exception is thrown in your Future callback, it’s not caught by the Future and is thrown to the provided ExecutionContext.
But the current default Scala global ExecutionContext doesn’t register an UncaughtExceptionHandler for these fatal exceptions and your Future just hangs forever without notifying anything to anybody.
This issue is well known and a solution to the problem has already been merged into branch 2.10.x. But this issue is present in Scala 2.10.0 so it’s interesting to keep this issue in mind IMHO. Let’s explain clearly about it.
Exceptions can be contained by Future
Let’s write some stupid code with Futures.
12345678910111213141516171819202122
scala>importscala.concurrent._scala>importscala.concurrent.duration._// Take default Scala global ExecutionContext which is a ForkJoin Thread Poolscala>valec=scala.concurrent.ExecutionContext.globalec:scala.concurrent.ExecutionContextExecutor=scala.concurrent.impl.ExecutionContextImpl@15f445b7// Create an immediately redeemed Future with a simple RuntimeExceptionscala>valf=future(thrownewRuntimeException("foo"))(ec)f:scala.concurrent.Future[Nothing]=scala.concurrent.impl.Promise$DefaultPromise@27380357// Access brutally the value to show that the Future contains my RuntimeExceptionscala>f.valueres22:Option[scala.util.Try[Nothing]]=Some(Failure(java.lang.RuntimeException:foo))// Use blocking await to get Future resultscala>Await.result(f,2seconds)warning:therewere1featurewarnings;re-runwith-featurefordetailsjava.lang.RuntimeException:fooat$anonfun$1.apply(<console>:14)at$anonfun$1.apply(<console>:14)...
You can see that a Future can contain an Exception (or more generally Throwable).
* The following throwable objects are not contained in the future:
* - `Error` - errors are not contained within futures
* - `InterruptedException` - not contained within futures
* - all `scala.util.control.ControlThrowable` except `NonLocalReturnControl` - not contained within futures
and in the code, in several places, in map or flatMap for example, you can read:
12345
try{...}catch{caseNonFatal(t)=>pfailuret}
This means that every Throwable that is Fatal can’t be contained in the Future.Failure.
What’s a Fatal Throwable?
To define what’s fatal, let’s see what’s declared as non-fatal in NonFatal ScalaDoc.
1234567
* Extractor of non-fatal Throwables.
* Will not match fatal errors like VirtualMachineError
* (for example, OutOfMemoryError, a subclass of VirtualMachineError),
* ThreadDeath, LinkageError, InterruptedException, ControlThrowable, or NotImplementedError.
*
* Note that [[scala.util.control.ControlThrowable]], an internal Throwable, is not matched by
* `NonFatal` (and would therefore be thrown).
Let’s consider Fatal exceptions are just critical errors that can’t be recovered in general.
So what’s the problem?
It seems right not to catch fatal errors in the `Future, isn’t it?
But, look at following code:
123456
// Let's throw a simple Fatal exceptionscala>valf=future(thrownewNotImplementedError())(ec)f:scala.concurrent.Future[Nothing]=scala.concurrent.impl.Promise$DefaultPromise@59747b17scala>f.valueres0:Option[scala.util.Try[Nothing]]=None
Ok, the Future doesn’t contain the Fatal Exception as expected.
But where is my Fatal Exception if it’s not caught??? No crash, notification or whatever?
There should be an `UncaughtExceptionHandler at least notifying it!
The problem is in the default Scala ExecutionContext.
As explained in this issue, the exception is lost due to the implementation of the default global ExecutionContext provided in Scala.
try{newForkJoinPool(desiredParallelism,threadFactory,null,//FIXME we should have an UncaughtExceptionHandler, see what Akka doestrue)// Async all the way baby}catch{caseNonFatal(t)=>...}
Here it’s quite clear: there is no registered `UncaughtExceptionHandler.
As you can see, you can wait as long as you want, the Future is never redeemed properly, it just hangs forever and you don’t even know that a Fatal Exception has been thrown.
As explained in the issue, please note, if you use a custom ExecutionContext based on SingleThreadExecutor, this issue doesn’t appear!
In Scala 2.10.0, if you have a Fatal Exception in a Future callback, your Future just trashes the Fatal Exception and hangs forever without notifying anything.
Hopefully, due to this already merged PR, in a future delivery of Scala 2.10.x, this problem should be corrected.
To finish, in the same old good issue, Viktor Klang also raised the question of what should be considered as fatal or not:
there’s a bigger topic at hand here, the one whether NotImplementedError, InterruptedException and ControlThrowable are to be considered fatal or not.
Now play-json stand-alone is officially a stand-alone module in Play2.2. So you don’t have to use the dependency given in this article anymore but use Typesafe one like com.typesafe.play:play-json:2.2
You can take Play2 Scala Json API as a stand-alone library and keep using Json philosophy promoted by Play Framework anywhere.
play-json module is stand-alone in terms of dependencies but is a part & parcel of Play2.2 so it will evolve and follow Play2.x releases (and following versions) always ensuring full compatibility with play ecosystem.
play-json module has 3 ultra lightweight dependencies:
play-functional
play-datacommons
play-iteratees
These are pure Scala generic pieces of code from Play framework so no Netty or whatever dependencies in it.
You can then import play-json in your project without any fear of bringing unwanted deps.
play-json will be released with future Play2.2 certainly so meanwhile, I provide:
Even if the version is 2.2-SNAPSHOT, be aware that this is the same code as the one released in Play 2.1.0. This API has reached a good stability level. Enhancements and bug corrections will be brought to it but it’s production-ready right now.
Adding play-json 2.2-SNAPSHOT in your dependencies
Using play-json, you can get some bits of Play Framework pure Web philosophy.
Naturally, to unleash its full power, don’t hesitate to dive into Play Framework and discover 100% full Web Reactive Stack ;)
Thanks a lot to Play Framework team for promoting play-json as stand-alone module!
Lots of interesting features incoming soon ;)
Remember Datomisca is an opensource Scala API (sponsored by Pellucid and Zenexity) trying to enhance Datomic experience for Scala developers.
After evoking queries compiled by Scala macros in previous article, I’m going to describe how Datomisca allows to create Datomic fact operations in a programmatic way and sending them to Datomic transactor using asynchronous/non-blocking API based on Scala 2.10 Future/ExecutionContext.
Datomic stores very small units of data called facts
Yes no tables, documents or even columns in Datomic. Everything stored in it is a very small fact.
Fact is the atomic unit of data
Facts are represented by the following tuple called Datom
1
datom= [entityattributevaluetx]
entity is an ID and several facts can share the same ID making them facts of the same entity. Here you can see that an entity is very loose concept in Datomic.
attribute is just a namespaced keyword : :person/name which is generally constrained by a typed schema attribute. The namespace can be used to logically identify an entity like “person” by regrouping several attributes in the same namespace.
value is the value of this attribute for this entity at this instant
tx uniquely identifies the transaction in which this fact was inserted. Naturally a transaction is associated with a time.
Facts are immutable & temporal
It means that:
You can’t change the past
Facts are immutable ie you can’t mutate a fact as other databases generally do: Datomic always creates a new version of the fact with a new value.
Datomic always grows
If you add more facts, nothing is deleted so the DB grows. Naturally you can truncate a DB, export it and rebuild a new smaller one.
You can foresee a possible future
From your present, you can temporarily add facts to Datomic without committing them on central storage thus simulating a possible future.
Reads/writes are distributed across different components
One Storage service storing physically the data (Dynamo DB/Infinispan/Postgres/Riak/…)
Multiple Peers (generally local to your app instances) behaving like high-speed synchronized cache obfuscating all the local data storage and synchro mechanism and providing the Datalog queries.
One (or several) transactor(s) centralizing the write mechanism allowing ACID transactions and notifying peers about those evolutions.
Immutability means known DB state is always consistent
You might not be up-to-date with central data storage as Datomic is distributed, you can even lose connection with it but the data you know are always consistent because nothing can be mutated.
This immutability concept is one of the most important to understand in Datomic.
Schema contrains entity attributes
Datomic allows to define that a given attribute must :
be of given type : String or Long or Instant etc…
have cardinality (one or many)
be unique or not
be fullsearchable or not
be documented
…
It means that if you try to insert a fact with an attribute and a value of the wrong type, Datomic will refuse it.
Datomic entity can also reference other entities in Datomic providing relations in Datomic (even if Datomic is not RDBMS). One interesting thing to know is that all relations in Datomic are bidirectional.
I hope you immediately see the link between these typed schema attributes and potential Scala type-safe features…
Author’s note : Datomic is more about evolution than mutation I’ll let you meditate this sentence linked to theory of evolution ;)
Adding a fact for the same entity will NOT update existing fact but create a new fact with same entity-id and a new tx.
Retract a Fact
1
[:db/retractentity-idattributevalue]
Retracting a fact doesn’t erase any fact but just tells: “for this entity-id, from now, there is no more this attribute”
You might wonder why providing the value when you want to remove a fact? This is because an attribute can have a MANY cardinality in which case you want to remove just a value from the set of values.
In Datomic, you often manipulate groups of facts identifying an entity. An entity has no physical existence in Datomic but is just a group of facts having the same entity-id. Generally, the attributes constituting an entity are logically grouped under the same namespace (:person/name, :person/age…) but this is not mandatory at all.
Datomic provides 2 operations to manipulate entities directly
In Datomic, there are special entities built using the special attribute :db/ident of type Keyword which are said to be identified by the given keyword.
Datomisca’s preferred way to build Fact/Entity operations is programmatic because it provides more flexibility to Scala developers.
Here are the translation of previous operations in Scala:
importdatomisca._importDatomic._// creates a Namespacevalperson=Namespace("person")// creates a add-fact operation // It creates the datom (id keyword value _) from// - a temporary id (or a final long ID)// - the couple `(keyword, value)`valaddFact=Fact.add(DId(Partition.USER))(person/"name"->"Bob")// creates a retract-fact operationvalretractFact=Fact.retract(DId(Partition.USER))(person/"age"->123L)// creates identified valuesvalviolent=AddIdent(person.character/"violent")valdumb=AddIdent(person.character/"dumb")// creates a add-entity operationvaladdEntity=Entity.add(DId(Partition.USER))(person/"name"->"Bob",person/"age"->30L,person/"characters"->Set(violent.ref,dumb.ref))// creates a retract-entity operation from real Long ID of the entityvalretractEntity=Entity.retract(3L)valops=Seq(addFact,retractFact,addEntity,retractEntity)
Note that:
person / "name" creates the keyword :person/name from namespace person
DId(Partition.USER) generates a temporary Datomic Id in Partition USER. Please note that you can create your own partition too.
violent.ref is used to access the keyword reference of the identified entity.
ops = Seq(…) represents a collection of operations to be sent to transactor.
It compiles what’s between """…""" at compile-time and tells you if there are errors and then it builds Scala corresponding operations.
Ok it’s cool but if you look better, you’ll see there is some sugar in this Clojure code:
\${DId(Partition.USER)}
\$weak
\$dumb
You can use Scala variables and inject them into Clojure operations at compile-time as you do for Scala string interpolation
For Datomic queries, the compiled way is really natural but we tend to prefer programmatic way to build operations because it feels to be much more “scala-like” after experiencing both methods.
Last but not the least, let’s send those operations to Datomic Transactor.
In its Java API, Datomic Connection provides a transact asynchronous API based on a ListenableFuture. This API can be enhanced in Scala because Scala provides much more evolved asynchronous/non-blocking facilities than Java based on Scala 2.10 Future/ExecutionContext.
Future allows to implement your asynchronous call using continuation style based on Scala classic map/flatMap methods.
ExecutionContext is a great tool allowing to specify in which pool of threads your asynchronous call will be executed making it non-blocking with respect to your current execution context (or thread).
This new feature is really important when you work with reactive API such as Datomisca or Play too so don’t hesitate to study it further.
Let’s look at code directly to show how it works in Datomisca:
importdatomisca._importDatomic._// don't forget to bring an ExecutionContext in your scope… // Here is default Scala ExecutionContext which is a simple pool of threads with one thread per core by defaultimportscala.concurrent.ExecutionContext.Implicits.global// creates an URIvaluri="datomic:mem://mydatomicdn"// creates implicit connectionimplicitvalconn=Datomic.connect(uri)// a few operationsvalops=Seq(addFact,retractFact,addEntity,retractEntity)valres:Future[R]=Datomic.transact(ops)map{tx:TxReport=>// do something…// return a value of type R (anything you want)valres:R=…res}// Another example by building ops directly in the transact call and using flatMapDatomic.transact(Entity.add(id)(person/"name"->"toto",person/"age"->30L,person/"character"->Set(weak.ref,dumb.ref)),Entity.add(DId(Partition.USER))(person/"name"->"tutu",person/"age"->54L,person/"character"->Set(violent.ref,clever.ref)),Entity.add(DId(Partition.USER))(person/"name"->"tata",person/"age"->23L,person/"character"->Set(weak.ref,clever.ref)))flatMap{tx=>// do something…valres:Future[R]=…res}
Please note the tx: TxReport which is a structure returned by Datomic transactor containing information about last transaction.
In all samples, we create operations based on temporary ID built by Datomic in a given partition.
1
DId(Partition.USER)
But once you have inserted a fact or an entity into Datomic, you need to resolve the real final ID to use it further because the temporary ID is no more meaningful.
The final ID is resolved from the TxReport send back by Datomic transactor. This TxReport contains a map between temporary ID and final ID. Here is how you can use it in Datomisca:
Last week, we have launched Datomisca, our opensource Scala API trying to enhance Datomic experience for Scala developers.
Datomic is great in Clojure because it is was made for it. Yet, we believe Scala can provide a very good platform for Datomic too because the functional concepts found in Clojure are also in Scala except that Scala is a compiled and statically typed language whereas Clojure is dynamic. Scala could also bring a few features on top of Clojure based on its features such as static typing, typeclasses, macros…
This article is the first of a serie of articles aiming at describing as shortly as possible specific features provided by Datomisca.
Today, let’s present how Datomisca enhances Datomic queries.
An important aspect of queries to understand in Datomic is that a query is purely a static data structure and not something functional. We could compare it to a prepared statement in SQL: build it once and reuse it as much as you need.
Query has input/ouput parameters
In previous example:
:in enumerates input parameters
:find enumerates output parameters
When executing this query, you must provide the right number of input parameters and you will retrieve the given number of output parameters.
I see you’re a bit disappointed: a query as a string whereas in Clojure, it’s a real data structure…
This is actually the way the Java API sends query for now. Moreover, using strings like implies potential bad practices such as building queries by concatenating strings which are often the origin of risks of code injection in SQL for example…
But in Scala we can do a bit better using new Scala 2.10 features : Scala macros.
So, using Datomisca, when you write this code, in fact, the query string is parsed by a Scala macro:
If there are any error, the compilation breaks showing where the error was detected.
If the query seems valid (with respect to our parser), the String is actually replaced by a AST representing this query as a data structure.
The input/output parameters are infered to determine their numbers.
Please note that the compiled query is a simple immutable AST which could be manipulated as a Clojure query and re-used as many times as you want.
Without going in deep details, here you can see that the compiled version of q isn’t a Query[String] but a TypedQueryAuto2[DatomicData, DatomicData, DatomicData] being an AST representing the query.
TypedQueryAuto2[DatomicData, DatomicData, DatomicData] means you have:
2 input parameters $ ?name of type DatomicData and DatomicData
Last type parameter represents output parameter ?e of type DatomicData
Note : DatomicData is explained in next paragraph.
Datomisca wraps completely Datomic API and types. So Datomisca doesn’t let any Datomic/Clojure types perspirating into its domain and wraps them all in the so-called DatomicData which is the abstract parent trait of all Datomic types seen from Datomisca. For each Datomic type, you have the corresponding specific DatomicData:
DString for String
DLong for Long
DatomicFloat for Float
DSet for Set
DInstant for Instant
…
Why not using Pure Scala types directly?
Firstly, because type correspondence is not exact between Datomic types and Scala. The best sample is Instant: is it a java.util.Date or a jodatime.DateTime?
Secondly, we wanted to keep the possibility of converting Datomic types into different Scala types depending on our needs so we have abstracted those types.
This abstraction also isolates us and we can decide exactly how we want to map Datomic types to Scala. The trade-off is naturally that, if new types appear in Datomic, we must wrap them.
Keep in mind that Datomisca queries accept and return DatomicData
All query data used as input and output paremeters shall be DatomicData. When getting results, you can convert those generic DatomicData into one of the previous specific types (DString, DLong, … ).
From DatomicData, you can also convert to Scala pure types based on implicit typeclasses:
Note 1 : that current Scala query compiler is a bit restricted to the specific domain of Datomic queries and doesn’t support all Clojure syntax which might create a few limitations when calling Clojure functions in queries. Anyway, a full Clojure syntax Scala compiler is in the TODO list so these limitations will disappear once it’s implemented…
Note 2 : Current macro just infers the number of input/output parameters but, using Schema typed attributes that we will present in a future article, we will provide some deeper features such as parameter type inference.
Please note we made the database input parameter mandatory even if it’s implicit in when importing Datomic._ because in Clojure, it’s also required and we wanted to stick to it.
Compile-error if wrong number of inputs
If you don’t provide 2 input parameters, you will get a compile error because the query expects 2 input parameters.
1234567891011121314
// Following would not compile because query expects 2 input parametersvalresults:List[(DatomicData, DatomicData]=Datomic.q(queryFindByName, DString("John"))[info]Compiling1Scalasourceto/Users/pvo/zenexity/workspaces/workspace_pellucid/datomisca/samples/getting-started/target/scala-2.10/classes...[error]/Users/pvo/zenexity/workspaces/workspace_pellucid/datomisca/samples/getting-started/src/main/scala/GettingStarted.scala:87:overloadedmethodvalueqwithalternatives:[error][A, R(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)](query:datomisca.TypedQueryAuto1[A,R(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)], a:A)(implicitdb:datomisca.DDatabase, implicitddwa:datomisca.DD2Writer[A], implicitoutConv:datomisca.DatomicDataToArgs[R(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)])List[R(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)]<and>[error][R(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)](query:datomisca.TypedQueryAuto0[R(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)], db:datomisca.DDatabase)(implicitoutConv:datomisca.DatomicDataToArgs[R(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)])List[R(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)(inmethodq)]<and>[error][OutArgs<:datomisca.Args, T](q:datomisca.TypedQueryInOut[datomisca.Args1,OutArgs], d1:datomisca.DatomicData)(implicitdb:datomisca.DDatabase, implicitoutConv:datomisca.DatomicDataToArgs[OutArgs], implicitott:datomisca.ArgsToTuple[OutArgs,T])List[T]<and>[error][InArgs<:datomisca.Args](query:datomisca.PureQuery, in:InArgs)(implicitdb:datomisca.DDatabase)List[List[datomisca.DatomicData]][error]cannotbeappliedto(datomisca.TypedQueryAuto2[datomisca.DatomicData,datomisca.DatomicData,(datomisca.DatomicData, datomisca.DatomicData)], datomisca.DString)[error]valresults=Datomic.q(queryFindByName, DString("John"))[error]^[error]oneerrorfound[error](compile:compile)Compilationfailed
The compile error seems a bit long as the compiler tries a few different version of Datomic.q but just remind that when you see cannot be applied to (datomisca.TypedQueryAuto2[…, it means you provided the wrong number of input parameters.
Use query results
Query results are List[DatomicData…] depending on the output parameters inferred by the Scala macros.
In our case, we have 2 output parameters so we expect a List[(DatomicData, DatomicData)].
Using List.map (or headOption to get the first one only), you can then use pattern matching to specialize your (DatomicData, DatomicData) to (DLong, DInstant) as you expect.
123456
resultsmap{case(e:DLong,birth:DInstant)=>// converts into Scala typesvaleAsLong=e.as[Long]valbirthAsDate=birth.as[java.util.Date]}
Note 1: that when you want to convert your DatomicData, you can use our converters based on implicit typeclasses as following
Note 2: The Scala macro has not way just based on query to infer the real types of output parameters but ther is a TODO in the roadmap: using typed schema attributes presented in a future article, we will be able to do better certainly… Be patient ;)
////////////////////////////////////////////////////// using variable number of inputsvalq=Query("""[ :find ?e :in $ [?names ...] :where [?e :person/name ?names]]""")Datomic.q(q,database,DSet(DString("toto"),DString("tata")))////////////////////////////////////////////////////// using tuple inputsvalq=Query("""[ :find ?e ?name ?age :in $ [[?name ?age]] :where [?e :person/name ?name] [?e :person/age ?age]]""")Datomic.q(q,database,DSet(DSet(DString("toto"),DLong(30L)),DSet(DString("tutu"),DLong(54L))))////////////////////////////////////////////////////// using function such as fulltext searchvalq=Query("""[ :find ?e ?n :where [(fulltext $ :person/name "toto") [[ ?e ?n ]]]]""")////////////////////////////////////////////////////// using rulesvaltotoRule=Query.rules("""[ [ [toto ?e] [?e :person/name "toto"]] ]""")valq=Query("""[ :find ?e ?age :in $ % :where [?e :person/age ?age] (toto ?e)]""")////////////////////////////////////////////////////// using query specifying just the field in fact to be searchedvalq=Query("""[:find ?e :where [?e :person/name]]""")
Note that currently Datomisca reserializes queries to string when executing because Java API requires it but once Datomic Java API accepts that we pass List[List[Object]] instead of strings for query, the interaction will be more direct…
Next articles about Datomic operations to insert/retract facts or entities in Datomic using Datomisca.
Since I discovered Scala Macros with Scala 2.10, I’ve been really impressed by their power. But great power means great responsibility as you know. Nevertheless, I don’t care about responsability as I’m just experimenting. As if mad scientists couldn’t experiment freely!
Besides being a very tasty pelagic fish from scombroid family, Maquereau is my new sandbox project to experiment eccentric ideas with Scala Macros.
Here is my first experiment which aims at studying the concepts of pataphysics applied to Scala Macros.
I’ve heard people saying that programming is not math.
This is really wrong, programming is math.
And let’s be serious, how would you seek attention in urbane cocktails without
those cute little words such as functors, monoids, contravariance, monads?
She/He> What do you do?
You> I’m coding a list fold.
She/He> Ah ok, bye.
You> Hey wait…
She/He> What do you do?
You> I’m deconstructing my list with a catamorphism based on a F-algebra as underlying functor.
She/He> Whahhh this is so exciting! Actually you’re really sexy!!!
You> Yes I known insignificant creature!
Programming is also a bit of Physics
Code is static meanwhile your program is launched in a runtime environment which is dynamic and you must take these dynamic aspects into account in your code too (memory, synchronization, blocking calls, resource consumption…). For the purpose of the demo, let’s accept programming also implies some concepts of physics when dealing with dynamic aspects of a program.
Compiling is Programming Metaphysics
Between code and runtime, there is a weird realm, the compiler runtime which is in charge of converting static code to dynamic program:
The compiler knows things you can’t imagine.
The compiler is aware of the fundamental nature of math & physics of programming.
The compiler is beyond these rules of math & physics, it’s metaphysics.
Macro is Pataphysics
Now we have Scala Macros which are able:
to intercept the compiling process for a given piece of code
to analyze the compiler AST code and do some computation on it
to generate another AST and inject it back into the compile-chain
When you write a Macro in your own code, you write code which runs in the compiler runtime. Moreover a macro can go even further by asking for compilation from within the compiler: c.universe.reify{ some code }… Isn’t it great to imagine those recursive compilers?
So Scala macro knows the fundamental rules of the compiler. Given compiler is metaphysics, Scala macro lies beyond metaphysics and the science studying this topic is called pataphysics.
This science provides very interesting concepts and this article is about applying them to the domain of Scala Macros.
I’ll let you discover pataphysics by yourself on wikipedia
Let’s explore the realm of pataphysics applied to Scala macro development by implementing the great concept of patamorphism, well-known among pataphysicians.
In 1976, the great pataphysician, Ernst Von Schmurtz defined patamorphism as following:
A patamorphism is a patatoid in the category of endopatafunctors…
Explaining the theory would be too long with lots of weird formulas. Let’s just skip that and go directly to the conclusions.
First of all, we can consider the realm of pataphysics is the context of Scala Macros.
Now, let’s take point by point and see if Scala Macro can implement a patamorphism.
A patamorphism should be callable from outside the realm of pataphysics
A Scala macro is called from your code which is out of the realm of Scala macro.
A patamorphism can’t have effect outside the realm of pataphysics after execution
This means we must implement a Scala Macro that :
has effect only at compile-time
has NO effect at run-time
From outside the compiler, a patamorphism is an identity morphism that could be translated in Scala as:
1
defpataMorph[T](t:T):T
A patamorphism can change the nature of things while being computed
Even if it has no effect once applied, meanwhile it is computed, it can :
have side-effects on anything
be blocking
be mutable
Concerning these points, nothing prevents a Scala Macro from respecting those points.
A patamorphism is a patatoid
You may know it but patatoid principles require that the morphism should be customisable by a custom abstract seed. In Scala samples, patatoid are generally described as following:
123456
traitPatatoid{// Seed is specific to a Patatoid and is used to configure the sprout mechanism typeSeed// sprout is the classic namedefsprout[T](t:T)(seed:Seed):T}
So a patamorphism could be implemented as :
1
traitPataMorphismextendsPatatoid
A custom patamorphism implemented as a Scala Macro would be written as :
1234567
objectMyPataMorphismextendsPataMorphism{typeSeed=MyCustomSeeddefsprout[T](t:T)(seed:Seed):T=macrosproutImpl// here is the corresponding macro implementationdefsproutImpl[T:c1.WeakTypeTag](c1:Context)(t:c1.Expr[T])(seed:c1.Expr[Seed]):c1.Expr[T]={…}}
But in current Scala Macro API, this is not possible for a Scala Macro to override an abstract function so we can’t write it like that and we need to trick a bit. Here is how we can do simply :
12345678910111213141516171819202122232425
traitPatatoid{// Seed is specific to a Patatoid and is used to configure the sprout mechanism typeSeed// we put the signature of the macro implementation in the abstract traitdefsproutMacro[T:c1.WeakTypeTag](c1:Context)(t:c1.Expr[T])(seed:c1.Expr[Seed]):c1.Expr[T]}/** * PataMorphism */traitPataMorphismextendsPatatoid// Custom patamorphismobjectMyPataMorphismextendsPataMorphism{typeSeed=MyCustomSeed// the real sprout function expected for patatoiddefsprout[T](t:T)(implicitseed:Seed):T=macrosproutMacro[T]// the real implementation of the macro and of the patatoid abstract operationdefsproutMacro[T:c1.WeakTypeTag](c1:Context)(t:c1.Expr[T])(seed:c1.Expr[Seed]):c1.Expr[T]={…// Your implementation here…}}
Conclusion
We have shown that we could implement a patamorphism using a Scala Macro.
But the most important is the implementation of the macro which shall:
have effect only at compile-time (with potential side-effect, sync, blocking)
have NO effect at runtime
Please note that pataphysics is the science of exceptions so all previous rules are true as long as there are no exception to them.
Let’s implement a 1st sample of patamorphism called VerySeriousCompiler.
VerySeriousCompiler is a pure patamorphism which allows to change compiler behavior by :
Choosing how long you want the compilation to last
Displaying great messages at a given speed while compiling
Returning the exact same code tree given in input
VerySeriousCompiler is an identity morphism returning your exact code without leaving any trace in AST after macro execution.
VerySeriousCompiler is implemented exactly using previous patamorphic pattern and the compiling phase can be configured using custom Seed:
123456
/** Seed builder * @param duration the duration of compiling in ms * @param speed the speed between each message display in ms * @param messages the messages to display */defseed(duration:Long,speed:Long,messages:Seq[String])
When to use it?
VerySeriousCompiler is a useful tool when you want to have a coffee or discuss quietly at work with colleagues and fool your boss making him/her believe you’re waiting for the end of a very long compiling process.
To use it, you just have to modify your code using :
123456789
VerySeriousCompiler.sprout{…somecode…}//or even valxxx=VerySeriousCompiler.sprout{…somecodereturningsomething…}
Then you launch compilation for the duration you want, displaying meaningful messages in case your boss looks at your screen. Then, you have an excuse if your boss is not happy about your long pause, tell him/her: “Look, it’s compiling”.
Remember that this PataMorphism doesn’t pollute your code at runtime at all, it has only effects at compile-time and doesn’t inject any other code in the AST.
Usage
With default seed (5s compiling with msgs each 400ms)
1234567
importVerySeriousCompiler._// Create a class for excaseclassToto(name:String)// using default seedsprout(Toto("toto"))mustbeEqualTo(Toto("toto"))
If you compile:
12345678910111213141516171819202122232425
[info] Compiling 1 Scala source to /workspace_mandubian/maquereau/target/scala-2.11/classes...
[info] Compiling 1 Scala source to /workspace_mandubian/maquereau/target/scala-2.11/test-classes...
Finding ring kernel that rules them all...................
computing fast fourier transform code optimization....................
asking why Obiwan Kenobi...................
resolving implicit typeclass from scope....................
constructing costate comonad....................
Do you like gladiator movies?....................
generating language systemic metafunction....................
verifying isomorphic behavior....................
inflating into applicative functor...................
verifying isomorphic behavior...................
invoking Nyarlathotep to prevent crawling chaos....................
Hear me carefully, your eyelids are very heavy, you're a koalaaaaa....................
resolving implicit typeclass from scope...................
[info] PataMorphismSpec
[info]
[info] VerySeriousCompiler should
[info] + sprout with default seed
[info] Total for specification PataMorphismSpec
[info] Finished in xx ms
[info] 1 example, 0 failure, 0 error
[info]
[info] Passed: : Total 1, Failed 0, Errors 0, Passed 1, Skipped 0
[success] Total time: xx s, completed 3 f?vr. 2013 01:25:42
With custom seed (1s compiling with msgs each 200ms)
12345678910111213141516
// using custom seedsprout{vala="this is"valb="some code"valc=123Ls"msg $a $b $c"}(VerySeriousCompiler.seed(1000L,// duration of compiling in ms200L,// speed between each message display in msSeq(// the message to display randomly "very interesting message","cool message")))mustbeEqualTo("msg this is some code 123")
If you compile:
12345678910111213141516
[info] Compiling 1 Scala source to /workspace_mandubian/maquereau/target/scala-2.11/classes...
[info] Compiling 1 Scala source to /workspace_mandubian/maquereau/target/scala-2.11/test-classes...
toto..........
coucou..........
toto..........
coucou..........
[info] PataMorphismSpec
[info]
[info] VerySeriousCompiler should
[info] + sprout with custom seed
[info] Total for specification PataMorphismSpec
[info] Finished in xx ms
[info] 1 example, 0 failure, 0 error
[info]
[info] Passed: : Total 1, Failed 0, Errors 0, Passed 1, Skipped 0
[success] Total time: xx s, completed 3 f?vr. 2013 01:25:42
The Seed passed to the macro doesn’t belong to the realm of Scala Macro but to your code. In the macro, we don’t get the Seed type but the expression Expr[Seed]. So in order to use the seed value in the macro, we must evaluate the expression passed to the macro:
Please note that this code is a work-around because in Scala 2.10, you can’t evaluate any code as you want due to some compiler limitations when evaluating
an already typechecked tree in a macro. This is explained in this Scala issue
input code re-compiling before returning from macro
We don’t return directly the input tree in the macro even if it would be valid with respect to patamorphism contract.
But to test Macro a bit further, I decided to ”re-compile” the input code from within the macro. You can do that using following code:
1
reify(a.splice)
Using macro paradise
The maquereau project is based on Macro Paradise which is the experimental branch of Scala Macros.
This implementation of patamorphism doesn’t use any experimental feature from Macro Paradise but future samples will certainly.
Today, let’s talk a bit more about the JSON coast-to-coast design I had introduced as a buzz word in a previous article about Play2.1 Json combinators.
Sorry this is a very long article with tens of >140-chars strings: I wanted to put a few ideas on paper to present my approach before writing any line of code…
1) Manipulate pure data structure (JSON) from client to DB without any static model 2) Focus on the idea of pure data manipulation and data-flow management
The underlying idea is more global than just questioning the fact that we generally serialize JSON data to static OO models. I really want to discuss how we manipulate data between frontend/backend(s). I’d also like to reconsider the whole data flow from a pure functional point of view and not through the lens of technical constraints such as “OO languages implies static OO models”.
Recent evolutions in backend architecture tend to push (again) UI to the frontend (the client side). As a consequence, backends concentrate more and more on data serving, manipulation, transformation, aggregation, distribution and naturally some business logic. I must admit that I’ve always considered backend are very good data provider and not so good UI provider. So I won’t say it’s a bad thing.
From this point of view, the backend focuses on:
getting/serving data from/to clients
retrieving/distributing data from/to other backends
storing data in DB/cache/files/whatever locally/remotely
doing some business logic (outside data manipulation)… sometimes but not so often.
I consider data management is the reason of being of backend and also the finality of it.
The word “data” is everywhere and that’s why I use the term “data-centric approach” (even if I would prefer that we speak about “information” more than data but this is another discussion…)
With Internet and global mobility, data tend to be gathered, re-distributed, scattered and re-shared logically and geographically
When you develop your server, you can receive data from many different sources and you can exchange data with many actors.
In this context, backend is often just a chain link participating to a whole data flow. So you must consider the relations existing with other actors of this system.
Besides the simple “what does my backend receive, transmit or answer?”, it has become more important to consider the relative role of the backend in the whole data flow and not only locally. Basically, knowing your exact role in the data flow really impacts your technical design:
if your server must aggregate data from one backend which can respond immediately and another one which will respond tomorrow, do you use a runtime stateful framework without persistence for that?
if your server is just there to validate data before sending it to a DB for storage, do you need to build a full generic & static model for that?
if your server is responsible for streaming data in realtime to hundreds of clients, do you want to use a blocking framework ?
if your server takes part to a high-speed realtime transactional system, is it reasonable to choose ultra heavyweight frameworks ?
In the past, we often used to model our data to be used by a single backend or a restricted system. Data model weren’t evolving too much for a few years. So you could choose a very strict data model using normalization in RDBMS for ex.
But since a few years, nature of data and their usage has changed a lot:
same data are shared with lots of different solutions,
same data are used in very different application domains,
unstructured data storage have increased
formats of data evolve much faster than before
global quantity of data has increased exponentially
…
The temporal nature of data has changed drastically also with:
realtime data streaming
on fhe fly distributed data updates
very long-time persistence
immutable data keeping all updates without losing anything
…
Nothing tremendous until now, isn’t it?
This is exactly what you already know or do every day…
I wanted to remind that a backend system is often only an element of a more global system and a chain link in a more global data flow.
Now let’s try to consider the data flow through a backend system taking all those modern aspects into account!
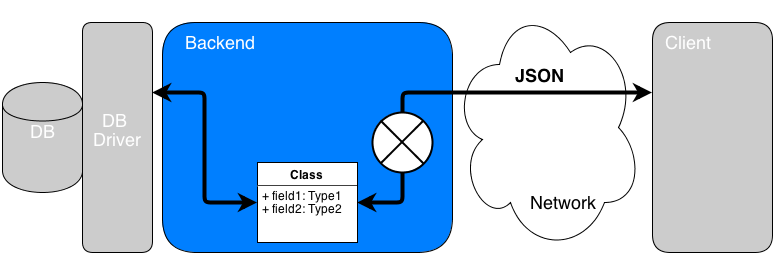
In the rest of this article, I’ll focus on a specific domain: the very classic case of backend-to-DB interaction.
For last 10 years, in all widespread enterprise platforms based on OO languages, we have all used those well-known ORM frameworks to manage our data from/to RDBMS. We have discovered their advantages and also their drawbacks. Let’s consider a bit how those ORM have changed our way of manipulating data.
After coding with a few different backend platforms, I tend to think we have been kind-of mesmerized into thinking it’s non-sense to talk to a DB from an OO language without going through a static language structure such as a class. ORM frameworks are the best witnesses of this tendency.
ORM frameworks lead us to:
Get some data (from client for ex) in a pure data format such as JSON (this format will be used in all samples because it’s very representative)
Convert JSON to OO structure such as class instance
Transmit class instance to ORM framework that translates/transmits it to the DB mystery limbo.
Pros
Classes are OO natural structure
Classes are the native structures in OO languages so it seems quite natural to use them
Classes imply structural validations
Conversion into classes also implies type constraint validations (and more specific constraints with annotations or config) in order to verify data do not corrupt the DB
Boundaries isolation
By performing the conversion in OO, the client format is completely decorrelated from DB format making them separated layers. Moreover, by manipulating OO structure in code, the DB can be abstracted almost completely and one can imagine changing DB later. This seems a good manner in theory.
Business logic compliant
Once converted, class instances can be manipulated in business logic without taking care about the DB.
Cons
Requirement for Business Logic is not the most frequent case
In many cases (CRUD being the 1st of all), once you get class instance, business logic is simply non-existing. You just pass the class to the ORM, that’s all. So you simply serialize to a class instance to be able to speak to ORM which is a pity.
ORM forces to speak OO because they can’t speak anything else
In many cases, the only needed thing is data validation with precise (and potentially complex) constraints. A class is just a type validator but it doesn’t validate anything else. If the String should be an email, your class sees it as a String. So, frameworks have provided constraint validators based on annotations or external configurations.
Classes are not made to manipulate/validate dynamic forms of data
Classes are static structure which can’t evolve so easily because the whole code depends on those classes and modifying a model class can imply lots of code refactoring. If data format is not clear and can evolve, classes are not very good. If data are polymorphic and can be seen using different views, it generally ends into multiplying the number of classes making your code hard to maintain.
Hiding DB more than abstracting it
ORM approach is just a pure OO view of relational data. It states that outside OO, nothing exists and no data can be modelled with something else than an OO structure.
So ORMs haven’t tried bringing DB structures to OO language but kind-of pushing OO to the DB and abstracting the DB data structure almost completely. So you don’t manipulate DB data anymore but you manipulate OO “mimicing” more or less DB structures.
Was OO really a so good choice against relational approach???
It seemed a good idea to map DB data to OO structures. But we all know the problems brought by ORM to our solutions:
How DB structures are mapped to OO?
How relations are managed by ORM?
How updates are managed in time? (the famous cache issues)
How transactions are delimited in a OO world?
How full compatibility between all RDBMS can be ensured?
etc…
I think ORM just moved the problems:
Before ORM, you had problems of SQL
After ORM, you had problems of ORM
Now the difference is that issues appear on the abstraction layer (ie the ORM) which you don’t control at all and not anymore at the lower-level DB layer. SQL is a bit painful sometimes but it is the DB native language so when you have an error, it’s generally far easier to find why and how to work around.
My aim here is not to tell ORM are bad (and there aren’t so bad in a few cases). I just want to point the OO deviation introduced by ORM in our way of modelling our data.
I’ll let you discover the subject by yourself and make your own mind and you don’t have to agree with me. As a very beginning, you can go to wikipedia there.
What interests me more is the fact that ORM brought a very systematic way of manipulating the data flowing through backend systems. ORM dictates that whatever data you manipulate, you must convert it to a OO structure before doing anything else for more or less good reasons. OO are very useful when you absolutely want to manipulate static typed structures. But in other cases, isn’t it better to use a List or a Map or more versatile pure data structure such as Json tree?
Let’s call it the All-Model Approach : no data can be manipulated without a static model and underlying abstraction/serialization mechanism.
The first move into the All-Model direction was quite logical in reaction to the difficulty of SQL integration with OO languages. Hibernate idea, for ex, was to abstract completely the relational DB models with OO structures so that people don’t care anymore with SQL.
As we all know, in software industry, when an idea becomes a standard of fact, as became ORMs, balance is rarely reached between 2 positions. As a consequence, lots of people decided to completely trash SQL in favor of ORM. That’s why we have seen this litany of ORM frameworks around hibernate, JPA, Toplink and almost nobody could escape from this global move.
After a few years of suffering more or less with ORM, some people have begun to re-consider this position seeing the difficulty they had to use ORM. The real change of mind was linked to the evolution of the whole data ecosystem linked to internet, distribution of data and mobility of clients also.
First, the move concerned the underlying layer: the DB.
RDBMS are really good to model very consistent data and provide robust transactions but not so good for managing high scalability, data distribution, massive updates, data streaming and very huge amount of data. That’s why we have seen these NoSQL new kids on the block initiated by Internet companies mainly.
Once again, the balance was upsetted: after the “SQL is evil” movement, there have been a funny “RDBMS is evil” movement. Extremist positions are not worth globally, what’s interesting is the result of NoSQL initiative. It allowed to re-consider the way we modelled our data: 100% normalized schema with full ACID transactions were no more the only possibility. NoSQL broke the rules: why not model your data as key/values, documents, graphs using redundancy, without full consistency if it fits better your needs?
I really think NoSQL breaking the holy RDBMS rule brought the important subject on the front stage: we care about the data, the way we manipulate them. We don’t need a single DB ruling them all but DB that answer to our requirements and not the other way… Data-Centric as I said before…
NoSQL DBs bring their own native API in general providing data representation fitting their own DB model. For ex, MongoDB is document oriented and a record is stored as a binary treemap.
But once again, we have seen ORM-kind API appear on top of those low-level API, as if we couldn’t think anymore in terms of pure data and not in terms of OO structures.
But the holy rule had been broken and next change would necessarily target ORM. So people rediscovered SQL could be used from modern languages (even OO) using simple mapping mechanism, simpler data structure (tuples, list, map, trees) and query facilities. Microsoft LINQ was a really interesting initiative… Modern languages such as Scala also bring interesting API based on the functional power of the language (cf Slick, Squeryl, Anorm etc…).
I know some people will tell replacing Class models by HashMaps makes the code harder to maintain and the lack of contract imposed by static typed classes results in code mess. I could answer I’ve seen exactly the same in projects having tens of classes to model all data views and it was also a mess impossible to maintain.
The question is not to forget static models but to use them only when required and keep simple and dynamic structures as much as possible.
ORM are still used widely but we can at least openly question their usefulness. Dictatorship is over and diversity is always better!
I want to question another fact in the way we model data:
we write generic OO model to have very strong static model and be independent of the DB.
we interact with those models using DAO providing all sorts of access functions.
we encapsulate all of that in abstract DB service layers to completely isolate from the DB.
Why? “Maybe I’ll change the DB and I’ll be able to do it…”
“Maybe I’ll need to re-use those DAO somewhere else…”
“Maybe Maybe Maybe…”
It works almost like superstition, as if making everything generic with strict isolated layers was the only way to protect us against failure and that it will make it work and be reused forever…
Do you change DB very often without re-considering the whole model to fit DB specific features?
Do you reuse code so often without re-considering the whole design?
I don’t say layered design and boundaries isolation is bad once again. I just say it has a cost and consequences that we don’t really consider anymore.
By trying to hide the DB completely, we don’t use the real power that DB can provide to us and we forget their specific capacities. There are so many DB types (sql, nosql, key/value, transactional, graph, column etc…) on the market and choosing the right one according to your data requirements is really important…
DB diversity gives us more control on our data so why hiding them behind too generic layers?
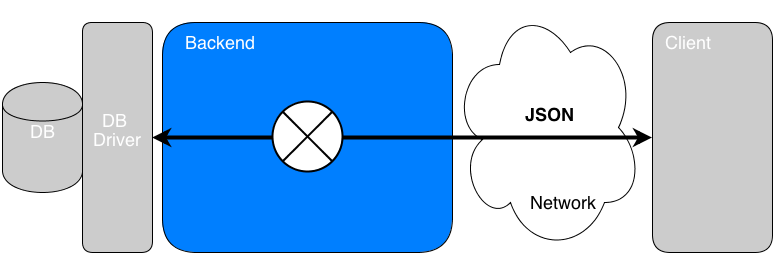
Let’s go back to our data-centric approach and try to manipulate data flow going through our backend system to the DB without OO (de)serialization in the majority of cases.
What I really need when I manipulate the data flow is:
being able to manipulate data directly
validating the data structure and format according to different constraints
transforming/aggregating data coming from different sources
I call it the Data-centric or No-Model approach. It doesn’t mean my data aren’t structured but that I manipulate the data as directly as possible without going through an OO model when I don’t need it.
As explained before, using the same design for everything seems a good idea because homogeneity and standardization is a good principle in general.
But “in general” is not “always” and we often confound homogeneity with uniformity in its bad meaning i.e. diversity loss.
That’s why I prefer speaking about “Data-Centric approach” than “No-Model”: the important is to ponder your requirements with respect to your data flow and to choose the right tool:
If you need to perform business logic with your data, it’s often better to work with static OO structures so using a model might be better
If you just need to validate and transform your data, then why going through a model which is completely artificial.
If you just need to manipulate a real-time data flow, then manipulate the flow directly and forget models.
Now stop philosophizing and go to practice with a very basic sample as a beginning : let’s manipulate a flow of JSON data in very simple case of CRUD.
Hey this is the famous “Json coast-to-coast” approach ;)
To illustrate this data-centric approach manipulating a pure data flow without OO serialization, let’s focus on a pure CRUD sample based on JSON. I won’t speak about the client side to make it shorter but don’t forget the JSON data flow doesn’t begin or end at backend boundaries.
I also don’t focus on real-time flow here because this is worth another discussion. Play2.1 provides us with one of the best platform for real-time web applications. First get accustomed with data-centric design and then consider real-time data management…
The CRUD case is a very good one for our subject:
CRUD implies no backend business logic at all
Backend receives data corresponding to entity, validates their format and directly transmit the data to the DB to be stored.
CRUD targets pure data resources and JSON is good to represent pure data in Web world.
CRUD is compliant to REST approach
REST is very interesting because it implies that every resource is reachable through a single URL and a HTTP verb from the Web. This is also another discussion about how we access or link data…
The CRUD sample is not really the right example to consider the impact of relative place in data flow on design. In CRUD, there are no temporal or dynamic requirements. But let’s stay simple for a beginning.
As there is no business logic in the CRUD caser, we can focus on backend boundaries:
Backend/Client
Backend/DB
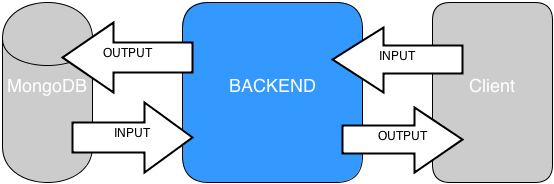
We can just consider the data received at previous boundaries:
What Input data is received from client or DB?
What Output data should be sent to DB or client?
In a summary, we can really consider the data-flow just in terms of inputs/outputs:
MongoDB provides a very versatile document-oriented data storage platform. MongoDB is not meant to model relational data but data structured as trees. So when you retrieve a document from Mongo, you also get all related data at once. In Mongo, normalized model is not really the main target and redundancy is not necessarily bad as long as you know what you do.
Mongo document are stored using BSON Binary JSON format which is simply inspired by JSON and optimized for binary storage.
Imagine you could get JSON (after validation) directly to or from Mongo without going through any superficial structure, wouldn’t it be really practical?
Please remark that serializing a JSON tree to a case-class and from a case class to a BSON document is just useless if you don’t have any business logic to fulfill with the case-class.
Play2.1 provides a very good JSON transformation API from/to any data structure. Converting JSON to BSON is not really an issue.
But now remember that we also want to be able to manage realtime data flow, to stream data from or to the DB (using Mongo capped collections for ex). Play2.x has been designed to be fully asynchronous/non-blocking. but unfortunately, default Java Mongo driver and its Scala counterpart (Casbah), despite their qualities, provide synchronous and blocking API.
But we are lucky since Stephane Godbillon decided to develop ReactiveMongo a full async/non-blocking Scala driver based on Akka and Play Iteratees (but independent of Play framework) and we worked together to develop a Play2.1/ReactiveMongo module providing all the tooling we need for JSON/BSON conversions in the context of Play2.1/Scala.
With Play/ReactiveMongo, you can simply send/receive JSON to/from Mongo and it’s transparently translated into BSON and vis versa.
When receiving JSON from client for Create and Update actions, we must be able to validate the Person structure without ID which will be generated at insertion:
Using Play2.1 JSON transformers (see my other article about it), you would validate this structure as following:
1234567
/** Full Person validator */valvalidatePerson:Reads[JsObject]=((__\'name).json.pickBranchand(__\'pw).json.pickBranchand(__\'addresses).json.copyFrom(addressesOrEmptyArray)and(__\'memberships).json.copyFrom(membershipsOrEmptyArray)).reduce
addressesOrEmptyArray
It’s a transformer validating an array of email strings and if not found it returns an empty array.
Here is how you can write this:
12345
/** Addresses validators */// if array is not empty, it validates each element as an email stringvalvalidateAddresses=Reads.verifyingIf((arr:JsArray)=>!arr.value.isEmpty)(Reads.list[String](Reads.email))// extracts "addresses" field or returns an empty array and then validates all addressesvaladdressesOrEmptyArray=((__\'addresses).json.pick[JsArray]orElseReads.pure(Json.arr()))andThenvalidateAddresses
membershipsOrEmptyArray
It is a transformer validating an array of memberships and if not found it returns an empty array.
First, let’s write a Membership validator searching for address which must be an email, group_name and a group_id.
12345
valmembership=((__\'address).json.pickBranch(Reads.of[JsString]keepAndReads.email)and(__\'group_name).json.pickBranchand(__\'group).json.pickBranch).reduce// reduce merges all branches in a single JsObject
Now, use it to validate the membership list.
1234
// if array is not empty, it validates each element as a membershipvalvalidateMemberships=Reads.verifyingIf((arr:JsArray)=>!arr.value.isEmpty)(Reads.list(membership))// extracts "memberchips" field or returns an empty array and then validates all membershipsvalmembershipsOrEmptyArray=((__\'memberships).json.pick[JsArray]orElseReads.pure(Json.arr()))andThenvalidateMemberships
For restricted update, the client sends just the part that should be updated in the document and not all the document.
Yet the validator must accept only authorized fields.
Here is how you can write it:
1234567891011
/** Person validator for restricted update */// creates an empty JsObject whatever Json is providedvalemptyObj=__.json.put(Json.obj())// for each field, if not found, it simply writes an empty JsObjectvalvalidatePerson4RestrictedUpdate:Reads[JsObject]=(((__\'name).json.pickBranchoremptyObj)and((__\'pw).json.pickBranchoremptyObj)and((__\'addresses).json.copyFrom(addresses)oremptyObj)and((__\'memberships).json.copyFrom(memberships)oremptyObj)).reduce// merges all results
addresses
This is the same as addressesOrEmptyArray but it doesn’t return an empty array if addresses are not found.
When a person document is retrieved from DB, this is the whole document and you may need to transform it before sending it to the output. In our case, let’s modify it as following:
prune the password (even if hashed)
prune the _id (because client already knows it if it requested it)
This can be done with the following JSON transformer:
123456
/** prunes _id * and then prunes pw */valoutputPerson=(__\'_id).json.pruneandThen(__\'pw).json.prune
Instead of waiting for Mongo to generate the ID, you can generate it using ReactiveMongo API BSONObjectID.generate before inserting it into Mongo.
So before sending JSON to Mongo, let’s add field "_id" : "GENERATED_ID" to validated JSON.
Here is the JSON transformer generating an ID:
1
valgenerateId=(__\'_id).json.put(BSONObjectID.generate.stringify)// this generates a new ID and adds it to your JSON
In JSON, BsonObjectID is represented as a String but to inform Mongo that it’s an ID and not a simple String, we use the following extended JSON notation:
As explained, using Play/ReactiveMongo, you don’t have to care about BSON because it deals with BSON/JSON conversion behind the curtain.
We could transform data received from Mongo in case we don’t really trust them.
But in my case, I trust Mongo as all inserted data are mine so no use to transform those input data from Mongo.
We just need to remove all JSON extended notation for _id or created when sending to the output.
The _id is pruned so no need to convert it.
So we just have to convert Json extended notation for created field. Here is the transformer:
12
// update duplicates full JSON and replaces "created" field by removing "$date" levelvalfromCreated=__.json.update((__\'created).json.copyFrom((__\'created\'$date).json.pick))
Play controller is the place to do that and we can write one action per REST action.
Please note that the whole code is in a single Controller in the sample to make it compact. But a good manner would be to put transformers outside the controller to be able to share them between controllers.
In the following samples, please notice the way we compose all Json transformers described previously as if we were piping them.
The action receives the ID of the person as a String and we only need to generate the right Mongo JSON format to retrieve the document.
Here is the Json Writes[String] that creates the extended JSON notation from ID:
defgetPerson(id:String)=Action{// builds a query from IDvalq=QueryBuilder().query(toObjectId.writes(id))Async{persons.find[JsValue](q).headOption.map{caseNone=>NotFound(Json.obj("res"->"KO","error"->s"person with ID $id not found"))caseSome(p)=>p.transform(outputPerson).map{jsonp=>Ok(resOK(Json.obj("person"->jsonp)))}.recoverTotal{e=>BadRequest(resKO(JsError.toFlatJson(e)))}}}}
Delete is exactly the same as Get in terms of input and it doesn’t require any output except to inform about success or failure.
So let’s give directly the deletePersoncode:
Restricted update is exactly the same as Full update except it validates the input JSON using validatePerson4RestrictedUpdate instead of validatePerson
So here is the updatePersonRestricted action code:
Many things in this article… Maybe too many…
Anyway, the subject is huge and deserves it.
This sample demonstrates it’s possible to transmit a JSON data-flow from client to DB without going through any static model. That’s why I speak about JSON coast-to-coast and I find it’s a very good pattern in many cases in our every-day-as-backend-designer life.
Just remind 3 things maybe:
data flow direct manipulation is possible, practical and useful.
pure data manipulation doesn’t lessen type-safety or data structuring as you control everything at the boundaries of your backend system.
static model is useful sometimes but not always so before writing generic classes, DAO everywhere, think about your real needs.
In the code sample, I don’t take into account the temporal behavior of data and the dynamic requirements of interactions with other elements of the data flow. But don’t forget this aspect in your backend design.
Finally, as you could see, ReactiveMongo mixed with Play2.1 JSON API provides us with a really good toolbox for data-centric approach. It also allows to deal with realtime data flow to design so-called reactive applications (which is also the reason of being of Play2 framework).
A relatively short article, this time, to present an experimental feature developed by Sadek Drobi (@sadache) & I (@mandubian) and that we’ve decided to integrate into Play-2.1 because we think it’s really interesting and useful.
So you write 4 lines for this case class.
You know what? We have had a few complaints from some people who think it’s not cool to write a Reads[TheirClass] because usually Java JSON frameworks like Jackson or Gson do it behind the curtain without writing anything.
We argued that Play2.1 JSON serializers/deserializers are:
completely typesafe,
fully compiled,
nothing was performed using introspection/reflection at runtime.
But for some, this didn’t justify the extra lines of code for case classes.
We believe this is a really good approach so we persisted and proposed:
JSON simplified syntax
JSON combinators
JSON transformers
Added power, but nothing changed for the additional 4 lines.
As I’m currently in a mood of creating new expressions, after creating JSON coast-to-coast design, let’s call it JSON INCEPTION (cool word, quite puzzling isn’t it? ;)
Code injection is not dependency injection…
No Spring behind inception… No IOC, No DI… No No No ;)
I used this term on purpose because I know that injection is now linked immediately to IOC and Spring. But I’d like to re-establish this word with its real meaning.
Here code injection just means that we inject code at compile-time into the compiled scala AST (Abstract Syntax Tree).
So Json.reads[Person] is compiled and replaced in the compile AST by:
This is enabled by a new experimental feature introduced in Scala 2.10: Scala Macros
Scala macros is a new feature (still experimental) with a huge potential. You can :
introspect code at compile-time based on Scala reflection API,
access all imports, implicits in the current compile context
create new code expressions, generate compiling errors and inject them into compile chain.
Please note that:
We use Scala Macros because it corresponds exactly to our requirements.
We use Scala macros as an enabler, not as an end in itself.
The macro is a helper that generates the code you could write by yourself.
It doesn’t add, hide unexpected code behind the curtain.
We follow the no-surprise principle
As you may discover, writing a macro is not a trivial process since your macro code executes in the compiler runtime (or universe).
So you write macro code
that is compiled and executed
in a runtime that manipulates your code
to be compiled and executed
in a future runtime…
That’s also certainly why I called it Inception ;)
So it requires some mental exercises to follow exactly what you do. The API is also quite complex and not fully documented yet. Therefore, you must persevere when you begin using macros.
I’ll certainly write other articles about Scala macros because there are lots of things to say.
This article is also meant to begin the reflection about the right way to use Scala Macros.
Great power means greater responsability so it’s better to discuss all together and establish a few good manners…
With the so-called JSON inception, we have added a helper providing a trivial way to define your default typesafe Reads[T]/Writes[T]/Format[T] for case classes.
If anyone tells me there is still 1 line to write, I think I might become unpolite ;)