You might have seen on my twitter that my current company MFG Labs has opensourced the library Akka-Stream Extensions. We have developed it with Alexandre Tamborrino and Damien Pignaud for our recent production projects based on Typesafe Akka-Stream.
In this article, I won’t explain all the reasons that motivated our choice of Akka-Stream at MFG Labs and the road towards our library Akka-Stream Extensions. Here, I’ll focus on one precise aspect of our choice:
types… And I’ll tell you about a specific extension I’ve created for this project:ShapelessStream.
The code is there on github
Akka-Stream loves Types
As you may know, I’m a Type lover. Types are proofs and proofs are types. Proofs are what you want in your code to ensure in a robust & reliable way that it does what it pretends with the support of the compiler.
First of all, let’s remind that typesafety is a very interesting feature of Akka-Stream.
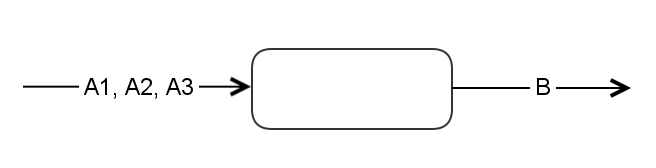
Akka-Stream most basic primitive Flow[A, B] represents a data-flow that accepts elements of type A and will return elements of type B. You can’t pass a C to it and you are sure that this flow won’t return any C for example.
At MFG Labs, we have inherited some Scala legacy code mostly based on Akka actors which provide a very good way to handle failures but which are not typesafe at all (till Akka Typed) and not composable. Developers using Akka tend to scatter the business logic in the code and it can become hard to maintain. It has appeared that in many cases where Akka was used to transform data in a flow, call external services, Akka-Stream would be a very good way to replace those actors:
- better type-safety,
- fluent & composable code with great builder DSL
- same Akka failure management
- buffer, parallel computing, backpressure out-of-the-box
Yes, it’s quite weird to say it but Akka-Stream helped us correct most problems that had been introduced using Akka (rightly or wrongly).
Multi-type flows
Ok, Akka-Stream promotes Types as first citizen in your data flows. That’s cool!
But it appears that you often need to handle multiple types in the same input channel:
When you control completely the types in input, you can represent input types by a classic ADT:
1 2 3 4 | |
… And manage it in Flow[A, B]:
1 2 3 4 5 | |
Nice but you need to wrap all input types in an ADT and this involves some boring code that can even be different for every custom flow.
Going further, in general, you don’t want to do that, you want to dispatch every element to a different flow according to its type:
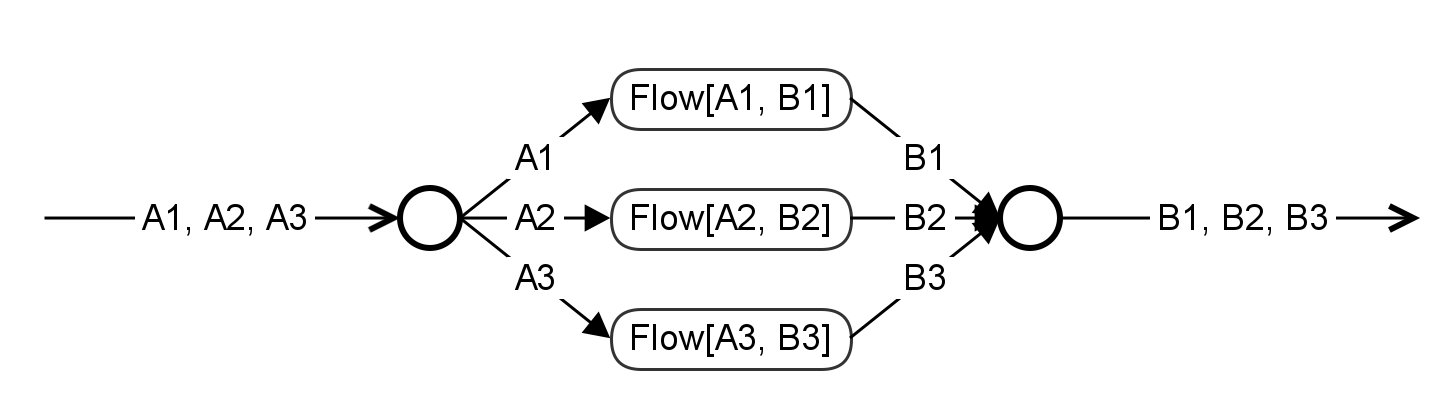
… and merge all results of all flows in one single channel…
… and every flow has its own behavior in terms of parallelism, bufferization, data generation and back-pressure…
In Akka-Stream, if you wanted to build a flow corresponding to the previous schema, you would have to use:
- a FlexiRoute for the input dispatcher
- a FlexiMerge for the output merger.
Have a look at the doc and see that it requires quite a bunch of lines to write one of those. It’s really powerful but quite tedious to implement and not so typesafe after all. Moreover, you certainly would have to write one FlexiRoute and one FlexiMerge per use-case as the number of inputs types and return types depend on your context.
Miles Sabin to the rescue
In my latest project, this dispatcher/flows/merger pattern was required in multiple places and as I’m lazy, I wanted something more elegant & typesafe if possible to build this kind of flow graphs.
Thinking in terms of pure types and from an external point of view, we can see the previous dispatcher/flows/merger flow graph in pseudo-code as:
1 2 3 4 | |
And to build the full flow graph, we need to provide a list of flows for all pairs of input/output types corresponding to our graph branches:
1
| |
In Shapeless, there are 2 very very very useful structures:
Coproductis a generalization of the well knownEither. You haveA or BinEither[A, B]. WithCoproduct, you can have more than 2 alternativesA or B or C or D. So, for our previous external view of flow graph, usingCoproduct, it could be written as:
1 2 3 4 | |
HListallows to build heterogenousListof elements keeping & tracking all types at compile time. For our previous list of flows, it would fit quite well as we want to match all input/output types of all flows. It would give:
1
| |
So, from an external point of view, the process of building our dispatcher/flows/merger flow graph looks like a Function taking aHlist of flowsin input and returning the builtFlow of Coproducts`:
1 2 | |
Let’s write it in terms of Shapeless Scala code:
1 2 3 4 5 6 7 8 9 | |
Fantastic !!!
Now the question is how can we build at compile-time this
Flow[CIn, COut, Unit]from anHListofFlowsand be sure that the compiler checks all links are correctly typed and all types are managed by the provided flows?
Akka-Stream Graph Mutable builders
An important concept in Akka-Stream is the separation of concerns between:
- constructing/describing a data-flow
- materializing with live resources (like actor system)
- running the data-flow by plugging live sources/sinks on it (like web, file, hdfs, queues etc…).
For the curious, you find the same idea in scalaz-stream but in a FP-purer way as scalaz-stream directly relies on
Freeconcepts that formalize this idea quite directly.
Akka-Stream has taken a more custom way to respond to these requirements. To build complex data flows, it provides a very nice DSL described here. This DSL is based on the idea of a mutable structure used while building your graph until you decide to fix it definitely into an immutable structure.
An example from the doc:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
builder is the mutable structure used to build the flow graph using the DSL inside the {...} block.
The value g is the immutable structure resulting from the builder that will later be materialized and run using live resources.
Please remark that once built, g value can reused and materialized/run several times, it is just the description of your flow graph.
This idea of mutable builders is really interesting in general: mutability in the small can help a lot to make your building block efficient and easy to write/read without endangering immutability in the large.
Hacking mutable builders with Shapeless
My intuition was to hack these mutable Akka-Stream builders using Shapeless type-dependent mechanics to build a Flow of Coproducts from an HList of Flows…
Let’s show the real signature of coproductFlow:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Frightening!!!!!!!
No, don’t be, it’s just the transcription in types of the requirements to build the full flow.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
The Scala code might seem a bit ugly to a few of you. That’s not false but keep in mind what we have done: mixing shapeless-style recursive implicit typeclass inference with the versatility of Akka-Stream mutable builders… And we were able to build our complex flow graph, to check all types and to plug all together at compile-time…
Sample
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | |
FYI, Shapeless Coproduct provides a lot of useful operations on Coproducts such as unifying all types or merging Coproducts together.
Some compile errors now ?
Imagine you forget to manage one type of the Coproduct in the HList of flows:
1 2 3 4 5 6 | |
If you compile, it will produce this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
OUCHHHH, this is a mix of the worst error of Akka-Stream and the kind of errors you get with Shapeless :)
Don’t panic, breathe deep and just tell yourself that in this case, it just means that your types do not fit well
In general, the first line and the last lines are the important ones.
For input:
1 2 3 4 5 | |
It just means you try to plug a C == Int :+: String :+: Bool :+: CNil to a Int :+: String :+: CNil and the compiler is angry against you!!
For output:
1 2 3 4 5 | |
It just means you try to plug a Int :+: String :+: CNil to a C == Int :+: String :+: Bool :+: CNil and the compiler is 2X-angry against you!!!
Conclusion
Mixing the power of Shapeless compile-time type dependent structures and Akka-Stream mutable builders, we are able to build at compile-time a complex dispatcher/flows/merger flow graph that checks all types and all flows correspond to each other and plugs all together in a 1-liner…
This code is the first iteration on this principle but it appeared to be so efficient and I trusted the mechanism so much (nothing happens at runtime but just at compile-time) that I’ve put that in production two weeks ago. It runs like a charm.
Finally, there are a few specificities/limitations to know:
Wrapping input data into the
Coproductis still the boring part with some pattern matching potentially. But this is like Json/Xml validation, you need to validate only the data you expect. Yet I expect to reduce the work soon by providing a Scala macro that will generate this part for you as it’s just mechanical…Wrapping everything in
Coproductcould have some impact on performance if what you expect is pure performance but in my use-cases IO are so much more impacting that this is not a problem…coproductFlowis built with a custom FlexiRoute withDemandFromAllcondition & FlexiMerge usingReadAnycondition. This implies :the order is NOT guaranteed due to the nature of used FlexiRoute & FlexiMerge and potentially to the flows you provide in your HList (each branch flow has its own parallelism/buffer/backpressure behavior and is not necessarily a 1-to-1 flow).
the slowest branch will slow down all other branches (as with a broadcast). To manage these issues, you can add buffers in your branch flows to allow other branches to go on pulling input data
The future?
A macro generating the Coproduct wrapping flow
Some other flows based on Shapeless
Have more backpressured and typed fun…