Today, let’s talk a bit more about the JSON coast-to-coast design I had introduced as a buzz word in a previous article about Play2.1 Json combinators.
Sorry this is a very long article with tens of >140-chars strings: I wanted to put a few ideas on paper to present my approach before writing any line of code…
Direct access
Original idea
1) Manipulate pure data structure (JSON) from client to DB without any static model
2) Focus on the idea of pure data manipulation and data-flow management
The underlying idea is more global than just questioning the fact that we generally serialize JSON data to static OO models. I really want to discuss how we manipulate data between frontend/backend(s). I’d also like to reconsider the whole data flow from a pure functional point of view and not through the lens of technical constraints such as “OO languages implies static OO models”.
In the code sample, we’ll use ReactiveMongo and Play2.1-RC2 and explain why those frameworks fit our demonstation.
Philosophical Considerations
Data-centric approach
Recent evolutions in backend architecture tend to push (again) UI to the frontend (the client side). As a consequence, backends concentrate more and more on data serving, manipulation, transformation, aggregation, distribution and naturally some business logic. I must admit that I’ve always considered backend are very good data provider and not so good UI provider. So I won’t say it’s a bad thing.
From this point of view, the backend focuses on:
- getting/serving data from/to clients
- retrieving/distributing data from/to other backends
- storing data in DB/cache/files/whatever locally/remotely
- doing some business logic (outside data manipulation)… sometimes but not so often.
I consider data management is the reason of being of backend and also the finality of it.
The word “data” is everywhere and that’s why I use the term “data-centric approach” (even if I would prefer that we speak about “information” more than data but this is another discussion…)
Backend system is a chain-link in global data-flow
Data-centric doesn’t mean centralized data
- With Internet and global mobility, data tend to be gathered, re-distributed, scattered and re-shared logically and geographically
- When you develop your server, you can receive data from many different sources and you can exchange data with many actors.
In this context, backend is often just a chain link participating to a whole data flow. So you must consider the relations existing with other actors of this system.
Besides the simple “what does my backend receive, transmit or answer?”, it has become more important to consider the relative role of the backend in the whole data flow and not only locally. Basically, knowing your exact role in the data flow really impacts your technical design:
- if your server must aggregate data from one backend which can respond immediately and another one which will respond tomorrow, do you use a runtime stateful framework without persistence for that?
- if your server is just there to validate data before sending it to a DB for storage, do you need to build a full generic & static model for that?
- if your server is responsible for streaming data in realtime to hundreds of clients, do you want to use a blocking framework ?
- if your server takes part to a high-speed realtime transactional system, is it reasonable to choose ultra heavyweight frameworks ?
- …
Rise of temporal & polymorphic data flows
In the past, we often used to model our data to be used by a single backend or a restricted system. Data model weren’t evolving too much for a few years. So you could choose a very strict data model using normalization in RDBMS for ex.
But since a few years, nature of data and their usage has changed a lot:
- same data are shared with lots of different solutions,
- same data are used in very different application domains,
- unstructured data storage have increased
- formats of data evolve much faster than before
- global quantity of data has increased exponentially
- …
The temporal nature of data has changed drastically also with:
- realtime data streaming
- on fhe fly distributed data updates
- very long-time persistence
- immutable data keeping all updates without losing anything
- …
Nothing tremendous until now, isn’t it?
This is exactly what you already know or do every day…
I wanted to remind that a backend system is often only an element of a more global system and a chain link in a more global data flow.
Now let’s try to consider the data flow through a backend system taking all those modern aspects into account!
In the rest of this article, I’ll focus on a specific domain: the very classic case of backend-to-DB interaction.
For last 10 years, in all widespread enterprise platforms based on OO languages, we have all used those well-known ORM frameworks to manage our data from/to RDBMS. We have discovered their advantages and also their drawbacks. Let’s consider a bit how those ORM have changed our way of manipulating data.
The ORM prism of distortion
After coding with a few different backend platforms, I tend to think we have been kind-of mesmerized into thinking it’s non-sense to talk to a DB from an OO language without going through a static language structure such as a class. ORM frameworks are the best witnesses of this tendency.
ORM frameworks lead us to:
- Get some data (from client for ex) in a pure data format such as JSON (this format will be used in all samples because it’s very representative)
- Convert JSON to OO structure such as class instance
- Transmit class instance to ORM framework that translates/transmits it to the DB mystery limbo.
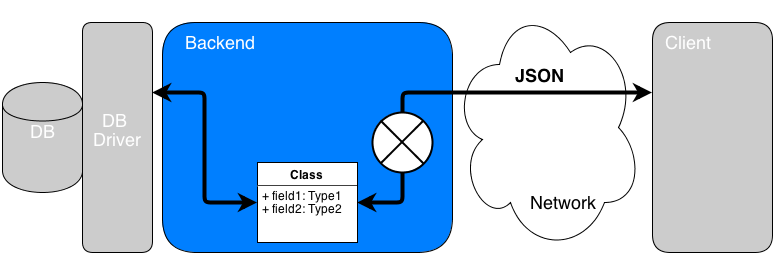
Pros
Classes are OO natural structure
Classes are the native structures in OO languages so it seems quite natural to use them
Classes imply structural validations
Conversion into classes also implies type constraint validations (and more specific constraints with annotations or config) in order to verify data do not corrupt the DB
Boundaries isolation
By performing the conversion in OO, the client format is completely decorrelated from DB format making them separated layers. Moreover, by manipulating OO structure in code, the DB can be abstracted almost completely and one can imagine changing DB later. This seems a good manner in theory.
Business logic compliant
Once converted, class instances can be manipulated in business logic without taking care about the DB.
Cons
Requirement for Business Logic is not the most frequent case
In many cases (CRUD being the 1st of all), once you get class instance, business logic is simply non-existing. You just pass the class to the ORM, that’s all. So you simply serialize to a class instance to be able to speak to ORM which is a pity.
ORM forces to speak OO because they can’t speak anything else
In many cases, the only needed thing is data validation with precise (and potentially complex) constraints. A class is just a type validator but it doesn’t validate anything else. If the String should be an email, your class sees it as a String. So, frameworks have provided constraint validators based on annotations or external configurations.
Classes are not made to manipulate/validate dynamic forms of data
Classes are static structure which can’t evolve so easily because the whole code depends on those classes and modifying a model class can imply lots of code refactoring. If data format is not clear and can evolve, classes are not very good. If data are polymorphic and can be seen using different views, it generally ends into multiplying the number of classes making your code hard to maintain.
Hiding DB more than abstracting it
ORM approach is just a pure OO view of relational data. It states that outside OO, nothing exists and no data can be modelled with something else than an OO structure.
So ORMs haven’t tried bringing DB structures to OO language but kind-of pushing OO to the DB and abstracting the DB data structure almost completely. So you don’t manipulate DB data anymore but you manipulate OO “mimicing” more or less DB structures.
Was OO really a so good choice against relational approach???
It seemed a good idea to map DB data to OO structures. But we all know the problems brought by ORM to our solutions:
- How DB structures are mapped to OO?
- How relations are managed by ORM?
- How updates are managed in time? (the famous cache issues)
- How transactions are delimited in a OO world?
- How full compatibility between all RDBMS can be ensured?
- etc…
I think ORM just moved the problems:
Before ORM, you had problems of SQL
After ORM, you had problems of ORM
Now the difference is that issues appear on the abstraction layer (ie the ORM) which you don’t control at all and not anymore at the lower-level DB layer. SQL is a bit painful sometimes but it is the DB native language so when you have an error, it’s generally far easier to find why and how to work around.
My aim here is not to tell ORM are bad (and there aren’t so bad in a few cases).
I just want to point the OO deviation introduced by ORM in our way of modelling our data.
I’ll let you discover the subject by yourself and make your own mind and you don’t have to agree with me. As a very beginning, you can go to wikipedia there.
The All-Model world
What interests me more is the fact that ORM brought a very systematic way of manipulating the data flowing through backend systems. ORM dictates that whatever data you manipulate, you must convert it to a OO structure before doing anything else for more or less good reasons. OO are very useful when you absolutely want to manipulate static typed structures. But in other cases, isn’t it better to use a List or a Map or more versatile pure data structure such as Json tree?
Let’s call it the All-Model Approach : no data can be manipulated without a static model and underlying abstraction/serialization mechanism.
The first move into the All-Model direction was quite logical in reaction to the difficulty of SQL integration with OO languages. Hibernate idea, for ex, was to abstract completely the relational DB models with OO structures so that people don’t care anymore with SQL.
As we all know, in software industry, when an idea becomes a standard of fact, as became ORMs, balance is rarely reached between 2 positions. As a consequence, lots of people decided to completely trash SQL in favor of ORM. That’s why we have seen this litany of ORM frameworks around hibernate, JPA, Toplink and almost nobody could escape from this global move.
Living in a changing world
After a few years of suffering more or less with ORM, some people have begun to re-consider this position seeing the difficulty they had to use ORM. The real change of mind was linked to the evolution of the whole data ecosystem linked to internet, distribution of data and mobility of clients also.
NoSQL emergence
First, the move concerned the underlying layer: the DB.
RDBMS are really good to model very consistent data and provide robust transactions but not so good for managing high scalability, data distribution, massive updates, data streaming and very huge amount of data. That’s why we have seen these NoSQL new kids on the block initiated by Internet companies mainly.
Once again, the balance was upsetted: after the “SQL is evil” movement, there have been a funny “RDBMS is evil” movement. Extremist positions are not worth globally, what’s interesting is the result of NoSQL initiative. It allowed to re-consider the way we modelled our data: 100% normalized schema with full ACID transactions were no more the only possibility. NoSQL broke the rules: why not model your data as key/values, documents, graphs using redundancy, without full consistency if it fits better your needs?
I really think NoSQL breaking the holy RDBMS rule brought the important subject on the front stage: we care about the data, the way we manipulate them. We don’t need a single DB ruling them all but DB that answer to our requirements and not the other way… Data-Centric as I said before…
Why ORM again for NoQSL?
NoSQL DBs bring their own native API in general providing data representation fitting their own DB model. For ex, MongoDB is document oriented and a record is stored as a binary treemap.
But once again, we have seen ORM-kind API appear on top of those low-level API, as if we couldn’t think anymore in terms of pure data and not in terms of OO structures.
But the holy rule had been broken and next change would necessarily target ORM. So people rediscovered SQL could be used from modern languages (even OO) using simple mapping mechanism, simpler data structure (tuples, list, map, trees) and query facilities. Microsoft LINQ was a really interesting initiative… Modern languages such as Scala also bring interesting API based on the functional power of the language (cf Slick, Squeryl, Anorm etc…).
I know some people will tell replacing Class models by HashMaps makes the code harder to maintain and the lack of contract imposed by static typed classes results in code mess. I could answer I’ve seen exactly the same in projects having tens of classes to model all data views and it was also a mess impossible to maintain.
The question is not to forget static models but to use them only when required and keep simple and dynamic structures as much as possible.
ORM are still used widely but we can at least openly question their usefulness. Dictatorship is over and diversity is always better!
Layered genericity as a talisman
I want to question another fact in the way we model data:
- we write generic OO model to have very strong static model and be independent of the DB.
- we interact with those models using DAO providing all sorts of access functions.
- we encapsulate all of that in abstract DB service layers to completely isolate from the DB.
Why?
“Maybe I’ll change the DB and I’ll be able to do it…”
“Maybe I’ll need to re-use those DAO somewhere else…”
“Maybe Maybe Maybe…”
It works almost like superstition, as if making everything generic with strict isolated layers was the only way to protect us against failure and that it will make it work and be reused forever…
Do you change DB very often without re-considering the whole model to fit DB specific features?
Do you reuse code so often without re-considering the whole design?
I don’t say layered design and boundaries isolation is bad once again. I just say it has a cost and consequences that we don’t really consider anymore.
By trying to hide the DB completely, we don’t use the real power that DB can provide to us and we forget their specific capacities. There are so many DB types (sql, nosql, key/value, transactional, graph, column etc…) on the market and choosing the right one according to your data requirements is really important…
DB diversity gives us more control on our data so why hiding them behind too generic layers?
The Data-Centric or No-Model approach
Let’s go back to our data-centric approach and try to manipulate data flow going through our backend system to the DB without OO (de)serialization in the majority of cases.
What I really need when I manipulate the data flow is:
- being able to manipulate data directly
- validating the data structure and format according to different constraints
- transforming/aggregating data coming from different sources
I call it the Data-centric or No-Model approach. It doesn’t mean my data aren’t structured but that I manipulate the data as directly as possible without going through an OO model when I don’t need it.
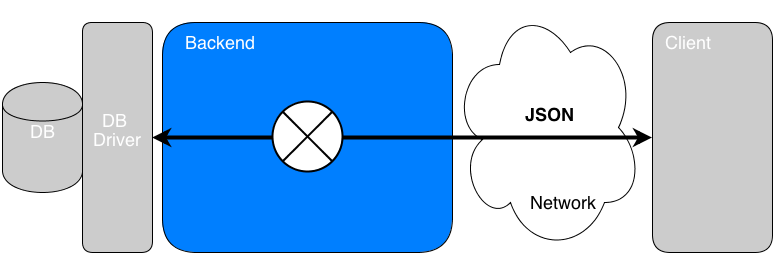
Should I trash the all-model approach?
Answer : NO… You must find the right balance.
As explained before, using the same design for everything seems a good idea because homogeneity and standardization is a good principle in general.
But “in general” is not “always” and we often confound homogeneity with uniformity in its bad meaning i.e. diversity loss.
That’s why I prefer speaking about “Data-Centric approach” than “No-Model”: the important is to ponder your requirements with respect to your data flow and to choose the right tool:
- If you need to perform business logic with your data, it’s often better to work with static OO structures so using a model might be better
- If you just need to validate and transform your data, then why going through a model which is completely artificial.
- If you just need to manipulate a real-time data flow, then manipulate the flow directly and forget models.
Now stop philosophizing and go to practice with a very basic sample as a beginning : let’s manipulate a flow of JSON data in very simple case of CRUD.
Hey this is the famous “Json coast-to-coast” approach ;)
Json Coast-to-Coast sample
To illustrate this data-centric approach manipulating a pure data flow without OO serialization, let’s focus on a pure CRUD sample based on JSON. I won’t speak about the client side to make it shorter but don’t forget the JSON data flow doesn’t begin or end at backend boundaries.
I also don’t focus on real-time flow here because this is worth another discussion. Play2.1 provides us with one of the best platform for real-time web applications. First get accustomed with data-centric design and then consider real-time data management…
The CRUD case is a very good one for our subject:
CRUD implies no backend business logic at all
Backend receives data corresponding to entity, validates their format and directly transmit the data to the DB to be stored.CRUD targets pure data resources and JSON is good to represent pure data in Web world.
CRUD is compliant to REST approach
REST is very interesting because it implies that every resource is reachable through a single URL and a HTTP verb from the Web. This is also another discussion about how we access or link data…
Thinking data flow in terms of Input/Output
The CRUD sample is not really the right example to consider the impact of relative place in data flow on design. In CRUD, there are no temporal or dynamic requirements. But let’s stay simple for a beginning.
As there is no business logic in the CRUD caser, we can focus on backend boundaries:
- Backend/Client
- Backend/DB
We can just consider the data received at previous boundaries:
- What Input data is received from client or DB?
- What Output data should be sent to DB or client?
In a summary, we can really consider the data-flow just in terms of inputs/outputs:
- Backend/Client input/output
- Backend/DB input/output
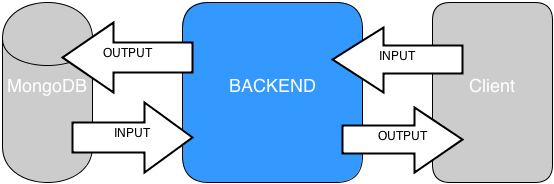
Why ReactiveMongo enables Json flow manipulation?
MongoDB provides a very versatile document-oriented data storage platform. MongoDB is not meant to model relational data but data structured as trees. So when you retrieve a document from Mongo, you also get all related data at once. In Mongo, normalized model is not really the main target and redundancy is not necessarily bad as long as you know what you do.
Mongo document are stored using BSON Binary JSON format which is simply inspired by JSON and optimized for binary storage.
Imagine you could get JSON (after validation) directly to or from Mongo without going through any superficial structure, wouldn’t it be really practical?
Please remark that serializing a JSON tree to a case-class and from a case class to a BSON document is just useless if you don’t have any business logic to fulfill with the case-class.
Play2.1 provides a very good JSON transformation API from/to any data structure. Converting JSON to BSON is not really an issue. But now remember that we also want to be able to manage realtime data flow, to stream data from or to the DB (using Mongo capped collections for ex). Play2.x has been designed to be fully asynchronous/non-blocking. but unfortunately, default Java Mongo driver and its Scala counterpart (Casbah), despite their qualities, provide synchronous and blocking API.
But we are lucky since Stephane Godbillon decided to develop ReactiveMongo a full async/non-blocking Scala driver based on Akka and Play Iteratees (but independent of Play framework) and we worked together to develop a Play2.1/ReactiveMongo module providing all the tooling we need for JSON/BSON conversions in the context of Play2.1/Scala.
With Play/ReactiveMongo, you can simply send/receive JSON to/from Mongo and it’s transparently translated into BSON and vis versa.
Sample Data format
Let’s try to manipulate a flow of data containing the following representation of a Person in JSON (or BSON)…
1 2 3 4 5 6 7 8 9 10 11 12 | |
A person consists in:
- a unique technical ID
- a name
- a hashed password which shouldn’t be transmitted outside anyway
- zero or more email addresses
- zero or more group memberships
- a creation date
A group membership consists in:
- the group email
- the group name
- the group ID
Data flow description
We will consider the following 4 CRUD actions:
- Create
- Get
- Delete
- Full/Restricted Update (Full document at once or a part of it)
CREATE
1
| |
Input
Backend receives the whole Person minus _id and created which is not yet known till insertion in DB.
1 2 3 4 5 6 7 8 9 10 | |
output
Backend sends the generated ID in a JSON object for ex.
1 2 3 | |
GET
1
| |
Input
Backend just receives the ID in the URL:
1
| |
Output
The whole person plus ID is sent back in JSON but for the demo, let’s remove a few fields we don’t want to send back:
_idwhich is not needed as the client knows itpwbecause this is a password even if hashed and we want it to stay in the server
1 2 3 4 5 6 7 8 9 10 | |
DELETE
1
| |
Input
Backend just receives the ID in the URL:
1
| |
Output
Nothing very interesting. Use a “200 OK” to stay simple
Full UPDATE
Macro update is meant to update a whole person document.
1
| |
Input
Backend just receives the ID in the URL:
1
| |
Updated person document is in the Post body:
1 2 3 4 5 6 7 8 9 10 | |
Output
Nothing very interesting. Use a “200 OK” to stay simple
Restricted UPDATE
Restricted update is meant to update just a part of a person document.
1
| |
Input
Backend just receives the ID in the URL:
1
| |
Updated person document is in the Post body:
1 2 3 4 5 6 7 8 | |
or
1 2 3 4 5 6 7 | |
or
1 2 3 | |
Output
Nothing very interesting. Use a “200 OK” to stay simple
Backend/Client boundary
Now that we know input/output data on our boundaries, we can describe how to validate these data and transform them within our backend system.
Input data from client (CREATE/ UPDATE)
Full person validation
When receiving JSON from client for Create and Update actions, we must be able to validate the Person structure without ID which will be generated at insertion:
1 2 3 4 5 6 7 8 9 10 | |
Using Play2.1 JSON transformers (see my other article about it), you would validate this structure as following:
1 2 3 4 5 6 7 | |
addressesOrEmptyArray
It’s a transformer validating an array of email strings and if not found it returns an empty array.
Here is how you can write this:
1 2 3 4 5 | |
membershipsOrEmptyArray
It is a transformer validating an array of memberships and if not found it returns an empty array.
First, let’s write a Membership validator searching for address which must be an email, group_name and a group_id.
1 2 3 4 5 | |
Now, use it to validate the membership list.
1 2 3 4 | |
Restricted person validation
For restricted update, the client sends just the part that should be updated in the document and not all the document. Yet the validator must accept only authorized fields.
Here is how you can write it:
1 2 3 4 5 6 7 8 9 10 11 | |
addresses
This is the same as addressesOrEmptyArray but it doesn’t return an empty array if addresses are not found.
1
| |
memberships
This is the same as membershipsOrEmptyArray but it doesn’t return an empty array if memberships are not found.
1
| |
Output data to Client (GET/DELETE)
When a person document is retrieved from DB, this is the whole document and you may need to transform it before sending it to the output. In our case, let’s modify it as following:
- prune the password (even if hashed)
- prune the _id (because client already knows it if it requested it)
This can be done with the following JSON transformer:
1 2 3 4 5 6 | |
Please note we don’t write it as following:
1 2 3 4 | |
Why? Because reduce merges results of both Reads[JsObject] so:
(__ \ '_id).json.pruneremoves_idfield but keepspw(__ \ 'pw).json.pruneremovespwfield but keeps_id
When reduce merges both results, it would return a Json with both _id and pw which is not exactly what we expect.
Backend/MongoDB boundary
Output to MongoDB
Now we can validate a received JSON as a Person structure.
But we need to write it to Mongo and Mongo has a few specificities.
ID in Mongo is a BsonObjectID
Instead of waiting for Mongo to generate the ID, you can generate it using ReactiveMongo API BSONObjectID.generate before inserting it into Mongo.
So before sending JSON to Mongo, let’s add field "_id" : "GENERATED_ID" to validated JSON.
Here is the JSON transformer generating an ID:
1
| |
BsonObjectID using JSON extended notation
In JSON, BsonObjectID is represented as a String but to inform Mongo that it’s an ID and not a simple String, we use the following extended JSON notation:
1 2 3 4 5 6 7 8 9 | |
Here is the JSON transformer to generate an ID using extended JSON notation:
1
| |
Date Extended JSON
created field is a Date represented as a JsNumber (a long) in JSON. When passing it to Mongo, we use the following extended JSON notation:
1 2 3 4 5 6 7 8 9 | |
Here is the final JSON transformer to generate a date using extended JSON notation:
1
| |
Input from Mongo
As explained, using Play/ReactiveMongo, you don’t have to care about BSON because it deals with BSON/JSON conversion behind the curtain.
We could transform data received from Mongo in case we don’t really trust them.
But in my case, I trust Mongo as all inserted data are mine so no use to transform those input data from Mongo.
We just need to remove all JSON extended notation for _id or created when sending to the output.
The _id is pruned so no need to convert it.
So we just have to convert Json extended notation for created field. Here is the transformer:
1 2 | |
Play2.1 controller as pipe plug
Now, we can:
- validate input JSON received from client,
- transform into Mongo format
- transform from Mongo format to output
Let’s plug the pipes all together:
- client inputs to Mongo outputs
- Mongo inputs to client outputs
Play controller is the place to do that and we can write one action per REST action.
Please note that the whole code is in a single Controller in the sample to make it compact. But a good manner would be to put transformers outside the controller to be able to share them between controllers.
In the following samples, please notice the way we compose all Json transformers described previously as if we were piping them.
Insert Person
When a Person document is created, there are 2 steps:
- validate the JSON using
validatePerson - transform JSON to fit Mongo format by:
- adding a generated
BSONObjectIDfield usinggenerateId - adding a generated
createddate field usinggenerateCreated
- adding a generated
Here is the JSON transformer to transform into Mongo format:
1 2 | |
Finally the insert action could be coded as:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
resOK and resKO are just function building JSON result with response status. Have a look at code for more info.
Get Person
The action receives the ID of the person as a String and we only need to generate the right Mongo JSON format to retrieve the document.
Here is the Json Writes[String] that creates the extended JSON notation from ID:
1
| |
Now the getPerson action code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Delete Person
Delete is exactly the same as Get in terms of input and it doesn’t require any output except to inform about success or failure.
So let’s give directly the deletePersoncode:
1 2 3 4 5 6 7 8 9 10 | |
Update Full Person
When updating a full person:
- we receive the ID in the URL
- we receive the new Json representing the person in the body
- we need to update the corresponding document in DB.
So we must do the following:
- validate input JSON using
validatePerson - transform the ID into MongoID JSON extended notation using
toObjectIddescribed previously - transform json into Update Json extended notation:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Here is the JSON transformer for update notation:
1 2 | |
Finally here is the corresponding updatePerson action code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Update Restricted Person
Restricted update is exactly the same as Full update except it validates the input JSON using validatePerson4RestrictedUpdate instead of validatePerson
So here is the updatePersonRestricted action code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Full Code
The whole sample can be found on Github json-coast-to-coast sample To test it, use a Rest client such as Postman or whatever.
Conclusion
Many things in this article… Maybe too many…
Anyway, the subject is huge and deserves it.
This sample demonstrates it’s possible to transmit a JSON data-flow from client to DB without going through any static model. That’s why I speak about JSON coast-to-coast and I find it’s a very good pattern in many cases in our every-day-as-backend-designer life.
Just remind 3 things maybe:
- data flow direct manipulation is possible, practical and useful.
- pure data manipulation doesn’t lessen type-safety or data structuring as you control everything at the boundaries of your backend system.
- static model is useful sometimes but not always so before writing generic classes, DAO everywhere, think about your real needs.
In the code sample, I don’t take into account the temporal behavior of data and the dynamic requirements of interactions with other elements of the data flow. But don’t forget this aspect in your backend design.
Finally, as you could see, ReactiveMongo mixed with Play2.1 JSON API provides us with a really good toolbox for data-centric approach. It also allows to deal with realtime data flow to design so-called reactive applications (which is also the reason of being of Play2 framework).
Have flowfun!